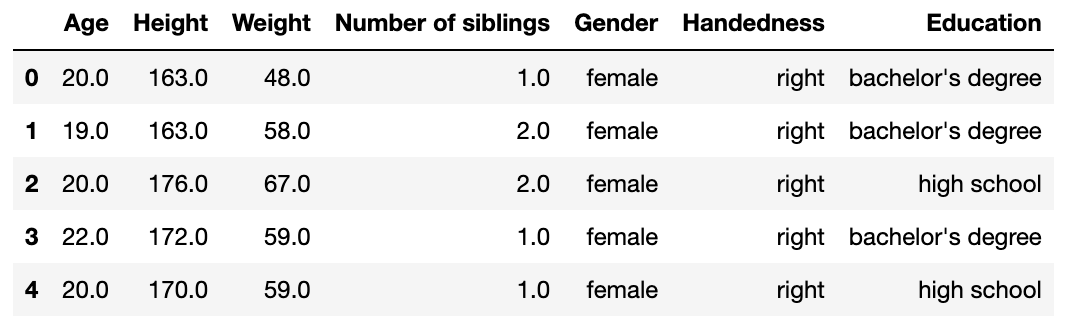
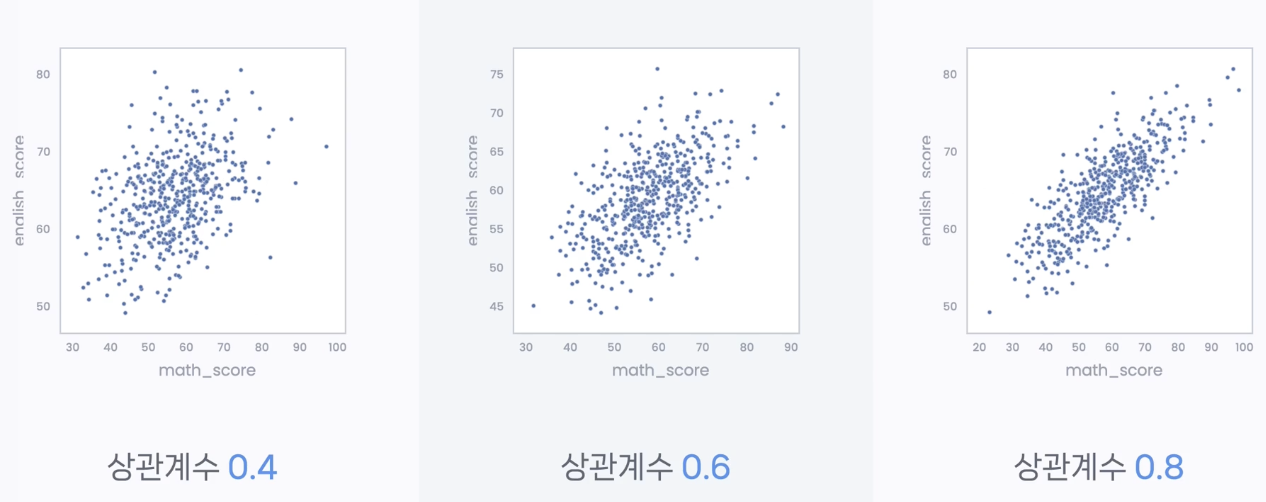
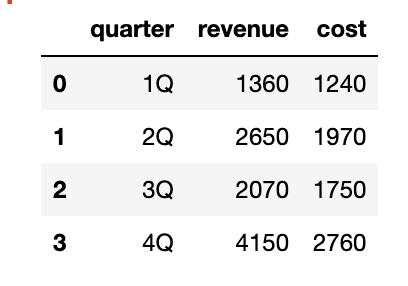
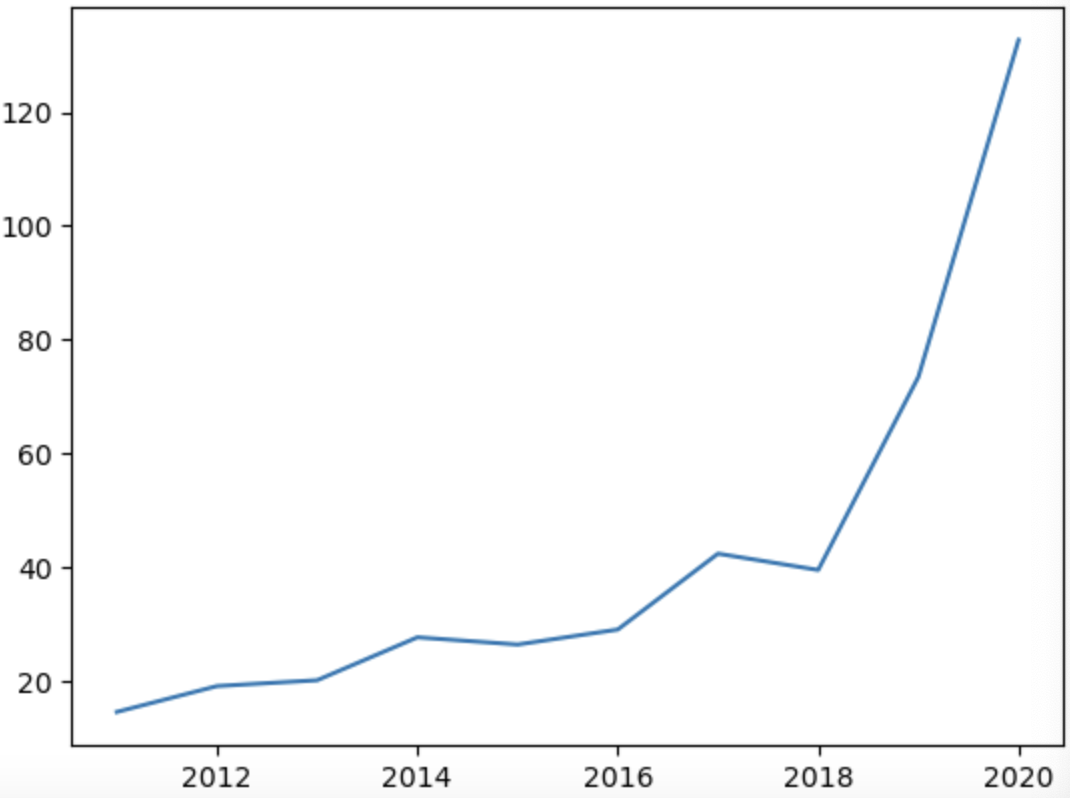
# 코드잇 데이터 사이언스 강의 듣는 중 - data set을 탐색적으로 살펴보면서 일반적인 패턴을 확인하는 것으로, 데이터 분석의 첫 단계.- row, column의 의미나, 분포, 연관성 등을 다양한 각도에서 확인하는 것. - 공식이 따로 있는 것이 아니라 데이터를 살펴보는 모든 것을 의미함. - 대개 시각적 기법을 가장 많이 사용함. ++ 즉, 데이터 분석의 초기 단계로,패턴, 이상치와 관례 등 기술적 통계부터 시각화를 사용해서 확인하는 것을 의미함. - 데이터의 특성과, 이후 분석과 가설 검정에 대한 정보를 제공함. - 그니깐 약간 말그대로 탐색적임. - 가설 검정 전 단계에 이걸로 뭘 할 수 있을 지 고민하는 단계임. => 그러니깐 기본적으로 표본이 어떤 지.. 결측지는 어떤지, 어디로 치..