# 코드잇 데이터 사이언스 강의 듣는 중
<상관 계수 Correlation Coefficient>
- 여러 상관 계수가 있지만, 피어슨 Pearson 상관 계수를 많이 씀.
1) 범위: -1 < 피어슨 Pearson 상관 계수 < +1
2) 피어슨 Pearson 상관 계수 = 0 --> 상관이 없음.
3) 피어슨 Pearson 상관 계수 = +- 1 --> 강한 상관
4) 1 > 피어슨 Pearson 상관 계수 > 0 : 정적 상관; x가 커지면 y가 증가
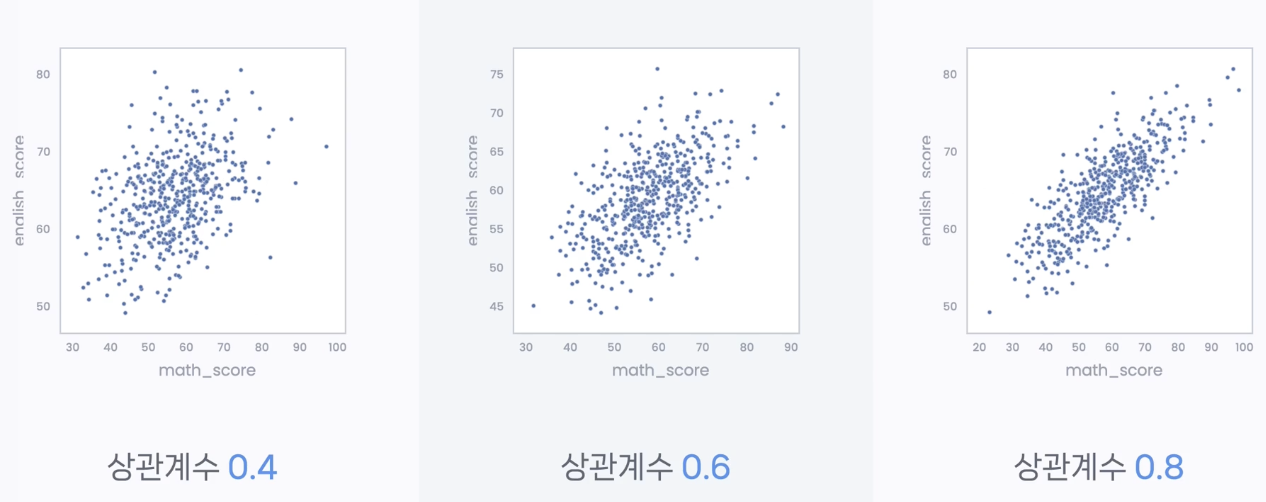
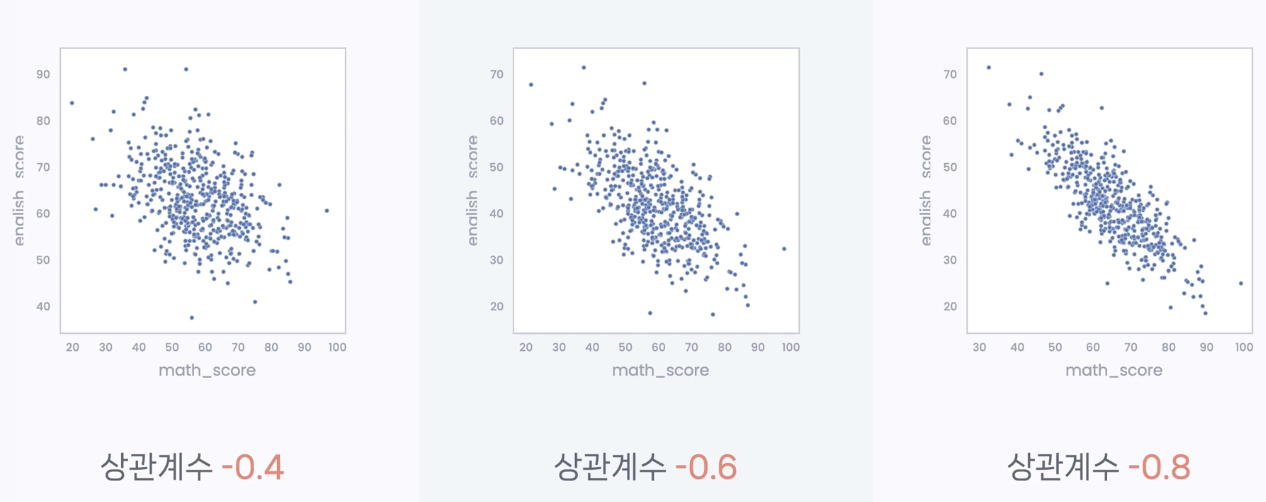
5) -1 <피어슨 Pearson 상관 계수 < 0 : 부적 상관; x가 커지면 y가 감소
++++

--> 피어슨 상관계수
--> x,y의 공분산 값을 각각의 표준편차의 곱으로 나눠준 것
<공분산 covariance>
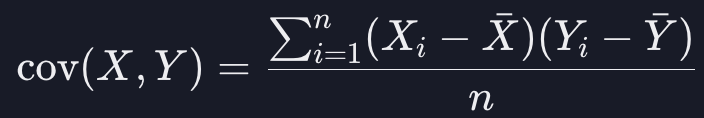
--> 각 값의 편차끼리 곱한 값을 n수로 나누어 준 것으로 변수의 관계의 방향성과 강도를 측정할 때 사용 가능함.
- 즉, 같이 움직이는 경향성임. 편차값이 커질수록 자료값이 퍼져있다는 뜻이고, 양수면 양의 상관관계이고 음수면 음의 상관관계임.
- but, 표준화가 안 된 값으로, 변수의 단위의 영향을 받아서 값이 커졌다 작아졌다 하기 때문에 해석이 어려움.
- so, 위의 피어슨 상관계수로 표준화를 해줘서 -1과 1사이의 값으로 만들어 비교할 수 있게 해주는 것.
<상관계수 구하기>
- .corr()
%matplotlib inline
import pandas as pd
df = pd.read_csv('data/exam.csv')
df.corr()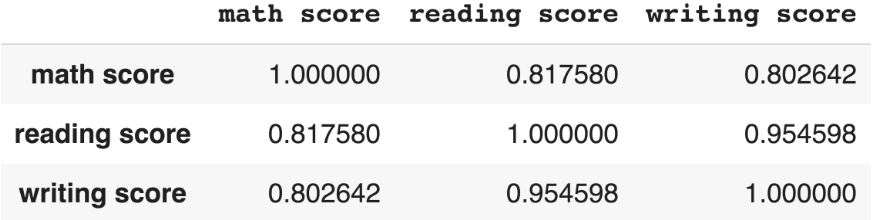
--> 난 맨날 수치인 상관 표로 봤었는데 ㅋㅋㅋ.ㅎ .95? 미친 상관이다... 저 정도면 다중 공선성 의심과 .. 걍 하나임.
- df.corr() 만 했을 때 에러가 뜨는 이유는, 문자열도 섞여있기 때문임.
- 따라서, numeric_only=True를 넣어서 숫자만 계산할 수 있게 하면됨
df.corr(numeric_only=True)
- 뒤에 벡터를 붙여 주면 그 벡터값과 나머지의 상관을 구할 수 있음.
- .sort_values(ascending=True)를 붙이면 작은 값부터 순서대로 나타냄.
df.corr(numeric_only=True)['total']
df.corr(numeric_only=True)['total'].sort_values(ascending=True)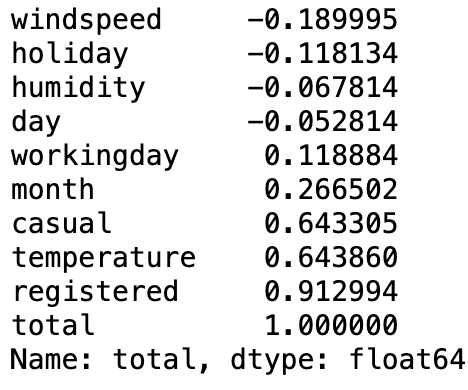
- 표가 눈에 잘 안 들어올 수도 있으니, heatmap으로 시각화 가능
--> 상관 값을 바로 넣어주면 됨 (아래 나옴)
sns.heatmap(df.corr(numeric_only=True))<시각화 하기>
1. scatter plot
2. reg plot
3. heatmap
1. scatter plot
#사이즈랑 배경 조절
sns.set_theme(rc={'figure.figsize' : (6,6)}, style='white')
sns.scatterplot(data=df, x='temperature', y='total')
plt.show()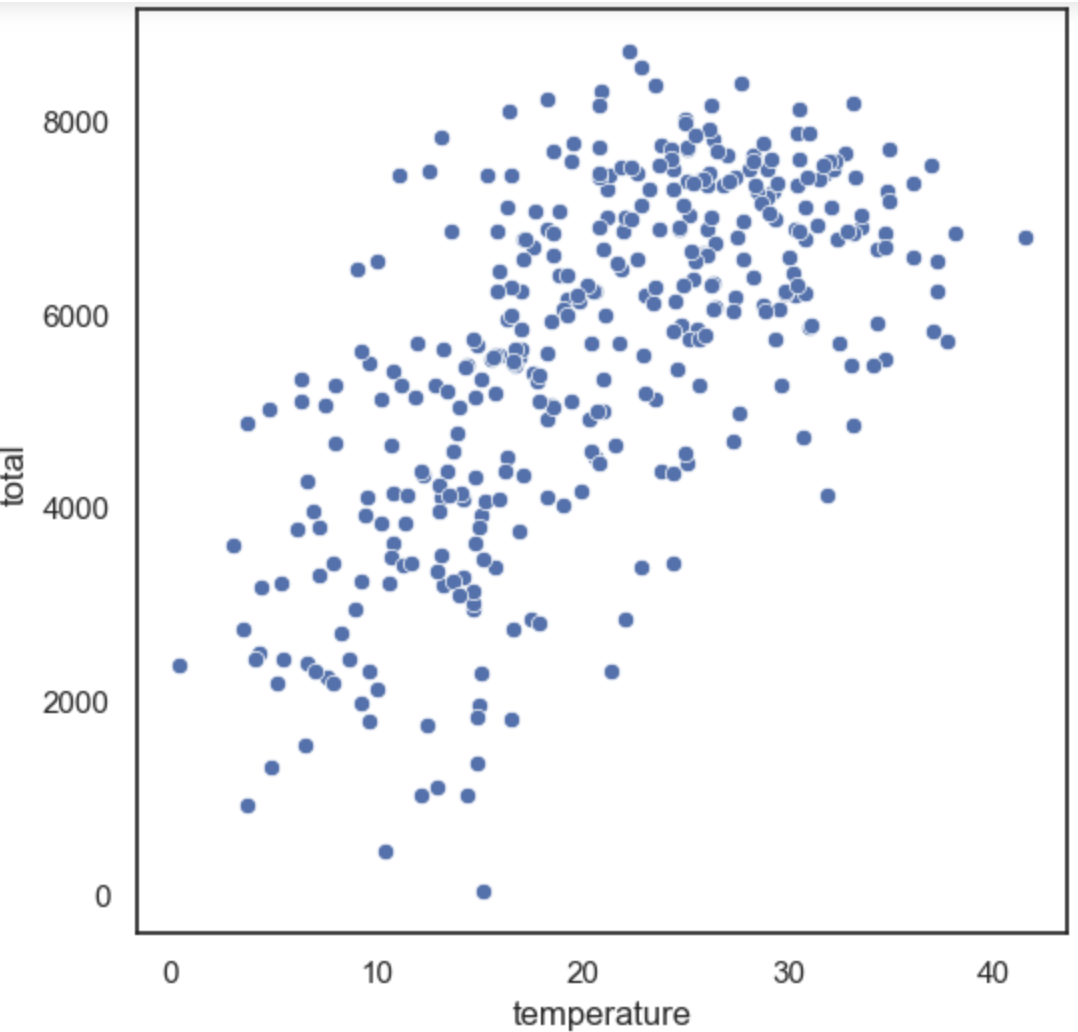
2. reg plot
- 회귀선 포함
sns.regplot(data=df, x='temperature', y='total')
plt.show()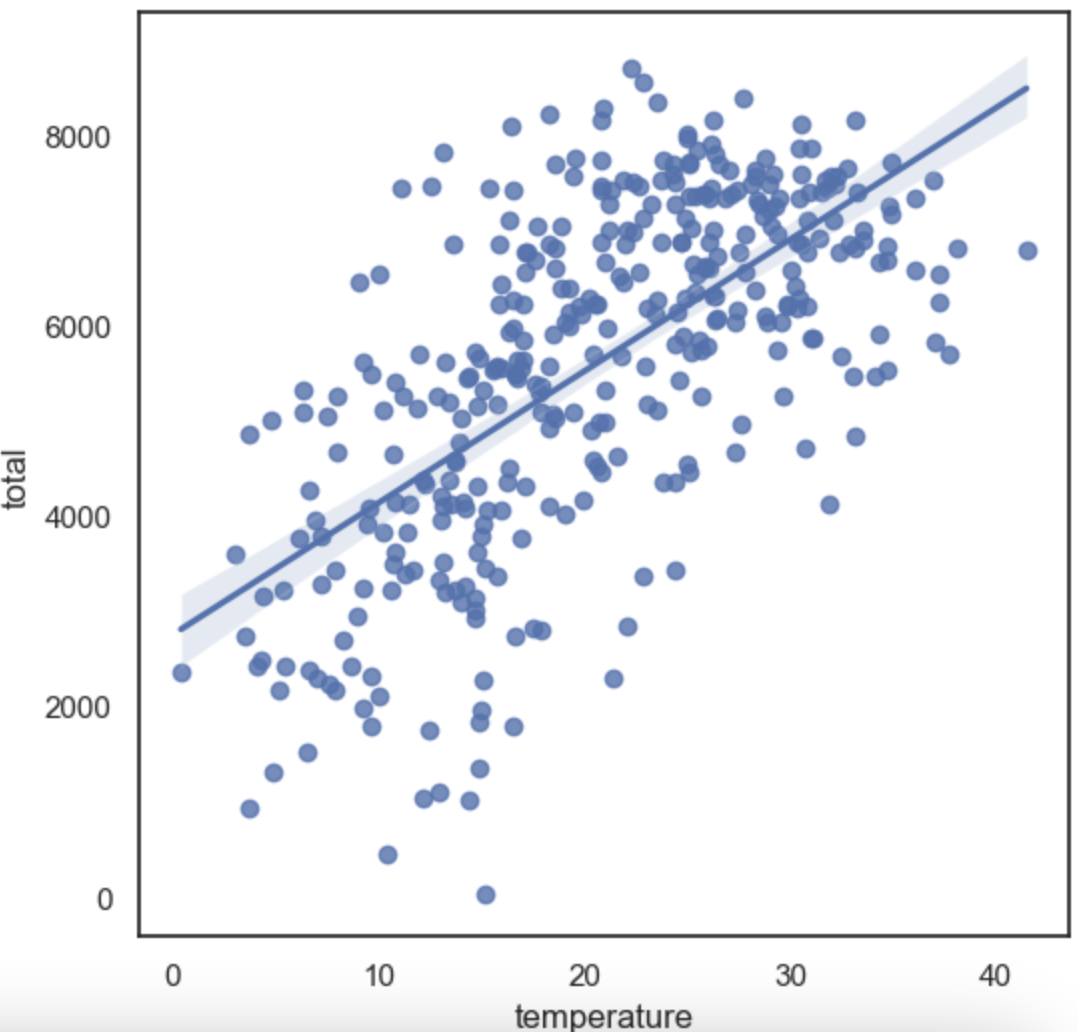
3. heatmap
- seaborn의 heatmap 메소드로 시각화 --> sns.heatmap()
%matplotlib inline
import pandas as pd
import seaborn as sns
df = pd.read_csv('data/exam.csv')
sns.heatmap(df.corr())

- 이거 matlab할 때 보던건 데..ㅎ
- 신경과학 수업은.. 그냥 다 시각화였지.
- 숫자 추가하려면 --> annot= True
sns.heatmap(df.corr(), annot=True)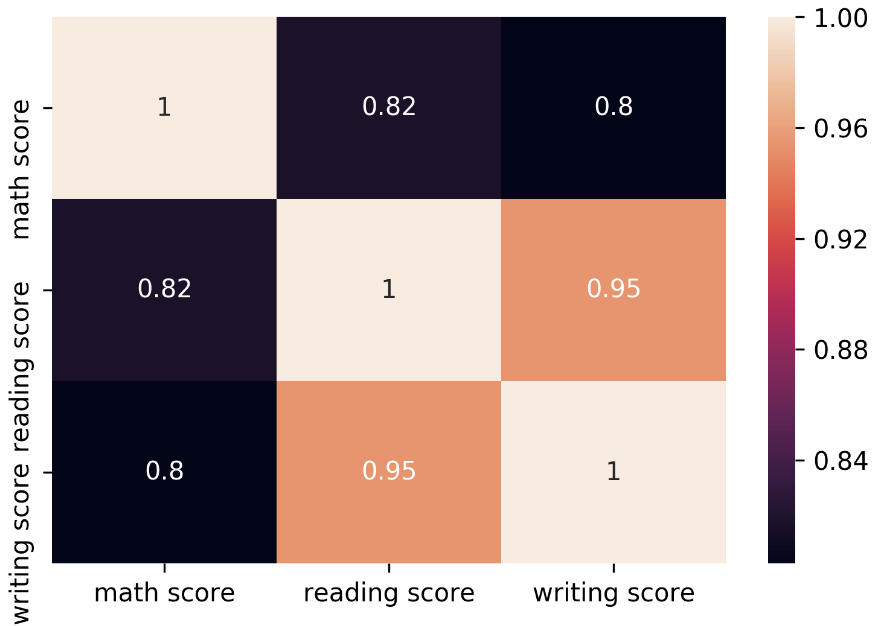
- 근데 히트맵은 헷갈리면 안 되는 것이, 그 데이터 상에서 가장 낮은 수치와 높은 수치를 기준으로 색깔이 칠해지는 듯.
- 0.8..........은 상관에서 굉장히 높은 수치이고 이걸........낮다고 할 수가 없는데...?
- 범위를 잘 살펴서 이런 건 주의해야 할 듯
- 강사님의 ..... 상관....해석이.. 조금 무리가 있어 보이는데.. 기본적으로
- 0.4 ≤ r < 0.6 낮은 상관
- 0.6 ≤ r < 0.8 중간 (상관이 있다)
- 0.8 ≤ r 높은 상관이다.
- 더 많은 데이터로 heatmap 활용하기
music = df.iloc[:, :19]
music.head()
sns.heatmap(music.corr())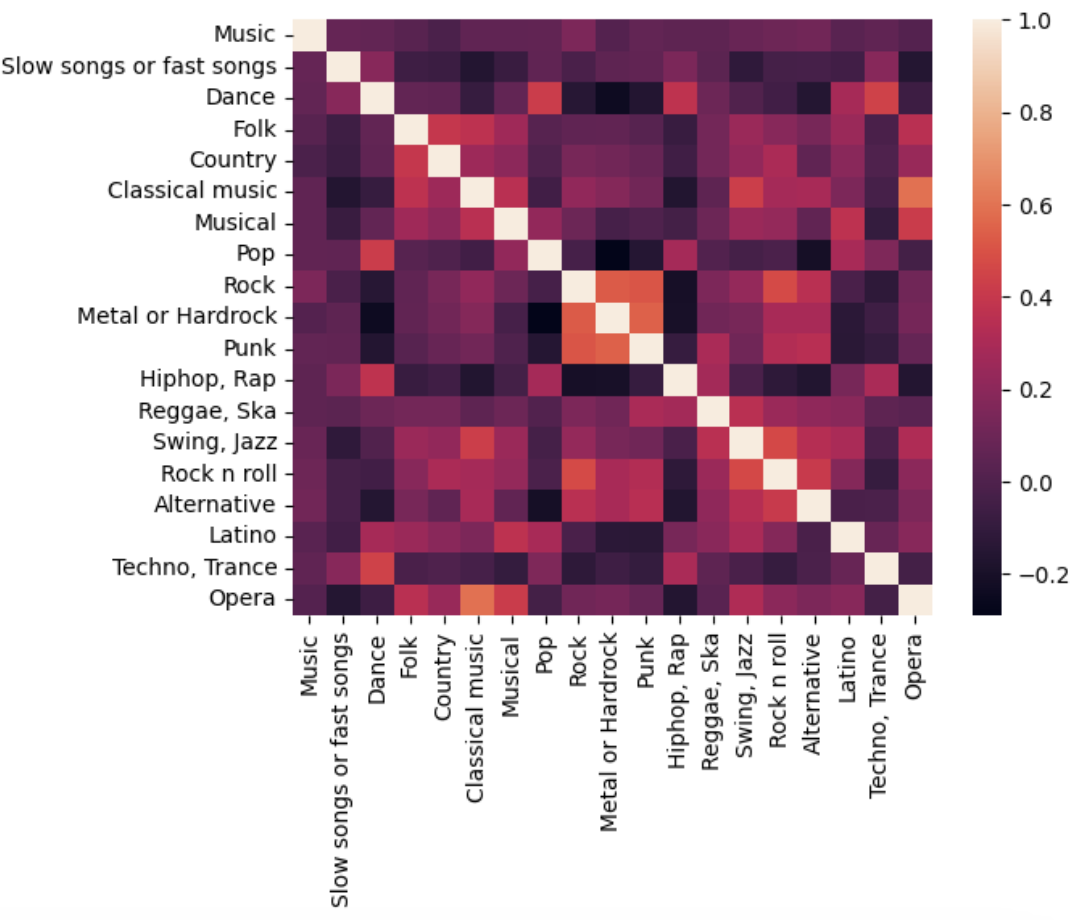
- 이건 화려하긴 한데.. 주의가 매우 필요할 듯.
- 상관 표로 보기는 pandas 버전이 2.0.0 이상인 경우, numeric_only = True를 추가
df.corr(numeric_only=True)
- 특정 열과의 상관만 뽑을 수 있음.
df.corr(numeric_only=True)['Age'].sort_values(ascending=False)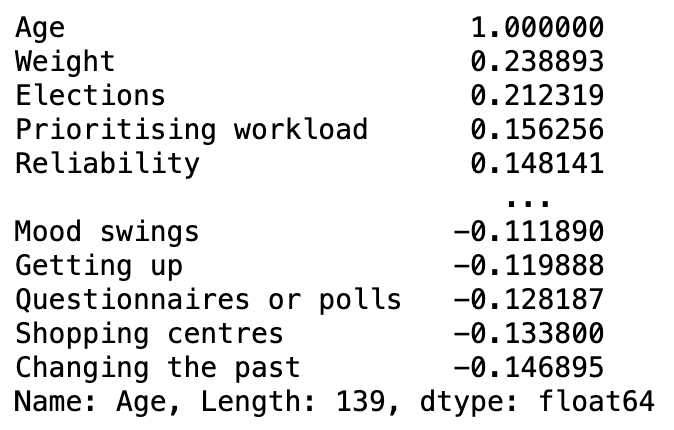
<예제 1>
- 음악과 일찍일어나는 사람과의 상관 관계 보기.
...... 이게..........쓰읍....맞는............게 아닌 거 같은데
- 어쨌든 1(아침에 쉽게 일어남)-5(힘들게 일어남) 5점 척도
- 일찍 일어나는 사람들('Getting up')이 많이 듣는 음악 찾기.
- 나는 고민하다가 df를 concat([,])으로 추가해서 만들었는데,
- concat([,]) --> df 합칠 때 사용
- axis=0 이 디폴트 값으로 행에 추가됨.
- 벡터로 넣으려고 했던 터라 위치는 맞는 데 값이 전부 Nan 이 뜬다면, 행으로 지정했기 때문
--> axis=1 추가해서 열로 지정해주면 Nan이 사라지고 원래의 값이 뜸.
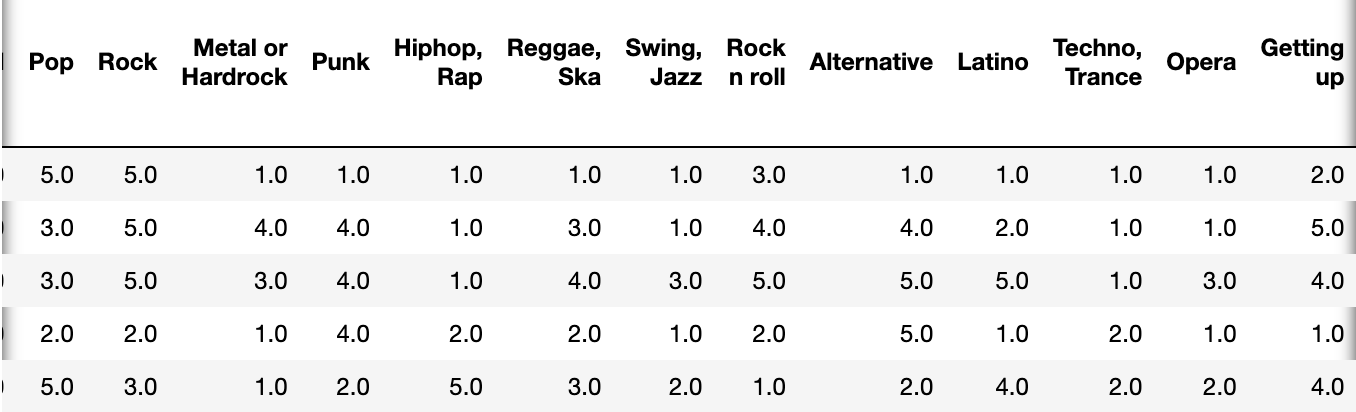
pd.concat([df.iloc[:, :19], df['Getting up']],axis=1)
ver1 (나)
#music = [df.iloc[:, :19]
music_getting_up_df = pd.concat([df.iloc[:, :19], df['Getting up']],axis=1)
music_getting_up_df.head()
sns.heatmap(music_getting_up_df.corr())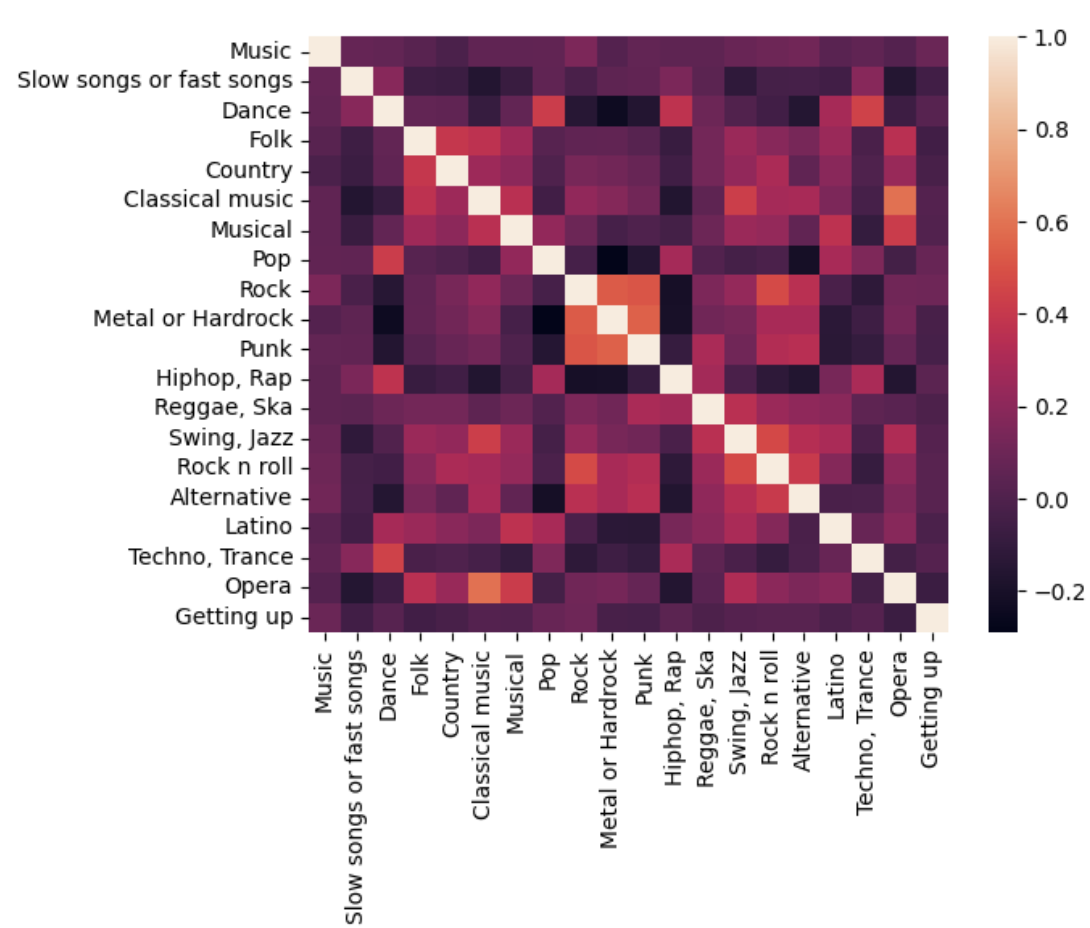
- 쉽게 일어나는 사람(1)과의 높은 상관을 보고 싶은 것이기에 부적 상관 값이 높은 것을 찾음... --> Opera
- 근데.. 그래 봤자.. -0.07 라고....... 이거 맞냐고......
- 우리과에서 이랬으면 .....조져졌음....
- 개인적으로 표나 숫자로 보는 게 더 편함. (물론 sorting이 되는 것은 세상 편함ㅎ)
music_getting_up_df.corr(numeric_only=True)['Getting up'].sort_values(ascending=False)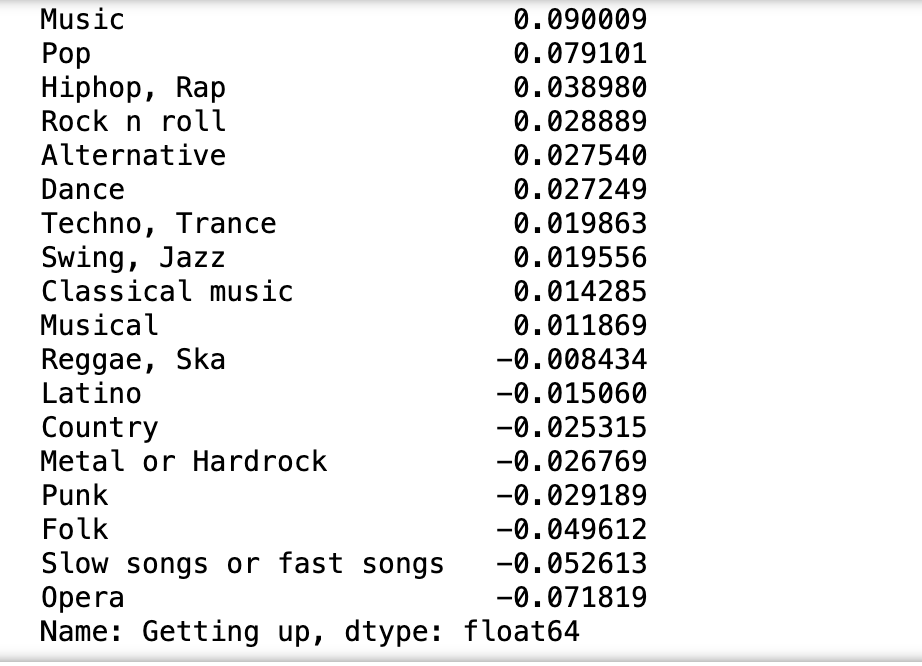
해설은 더 쉽고 짧게 했음.
- 조건문 처럼 corr.()를 사용했음.
ver2 해설
# getting up 궁금
brunch_df = df.corr(numeric_only=True)['Getting up']
# 음악 장르인 1-18번 칼럼까지 확인 필요
brunch_df[1:19]
# 오름차순으로 정리
brunch_df[1:19].sort_values(ascending=True)
#오름차순

<예제 2>
- 칼럼 별 관계보기.
- 해설에서는 각각 .loc로 상관 값을 구해서 비교했음.
df.corr().loc['Musical instruments', 'Writing']
#0.3441930532038243
- 그냥 데이터 프레임 만들어서 heatmap으로 한 번에 비교하니깐 편했음.
- 이렇게 대략적으로 볼때는 heatmap이 더 편한 듯.
hypothesis_df = df[['Branded clothing','Healthy eating', 'Musical instruments', 'New environment', 'Prioritising workload', 'Spending on looks', 'Workaholism', 'Writing', 'Writing notes']]
hypothesis_df.corr(numeric_only=True)
sns.heatmap(hypothesis_df.corr(numeric_only=True))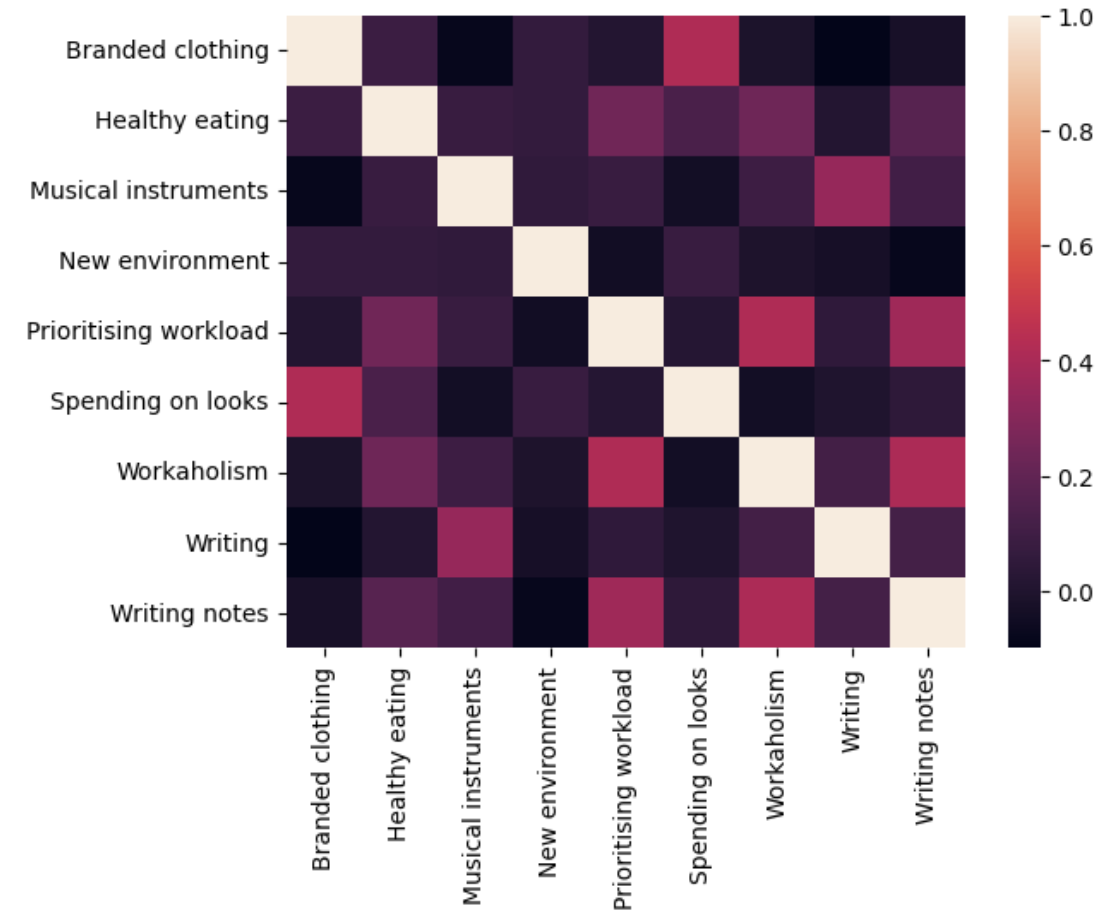
'Data Science > Statistics' 카테고리의 다른 글
| [기초 통계] 모집단과 표본, 기술통계와 추론 통계, 변수 종류, 데이터 분포 모양 (0) | 2024.06.11 |
|---|---|
| [Statistics] 군집 분석 cluster analysis, sns.clustermap() (3) | 2024.06.05 |
| [Statistics] mean, median, Q1, Q3, outlier, mode, .describe() (2) | 2024.06.02 |
| [Statistics] PDF 확률 밀도 함수, KDE kernel Density Estimation (0) | 2024.06.01 |
| [통계와 시각화] 선/막대/원 그래프, 히스토그램, box plot, 산포도 (0) | 2024.06.01 |