#코드잇 데이터 사이언스 강의 듣는 중
#데이터 사이언스 Toolkit renewal 버전과 이전 데이터 시각화 강의가 섞인 정리
<선 그래프>
- numpy처럼 matplotlib을 메소드로 쓸 수도 있지만, Pandas 플랏이 어차피 plt를 끌어다가 쓰는 것이라서 더 간단하게 사용가능.
import pandas as pd
import matplotlib.pyplot as plt
sales_df = pd.DataFrame({
'quarter' : ['1Q', '2Q', '3Q', '4Q'],
'revenue' : [1360, 2650, 2070, 4150],
'cost' : [1240, 1970, 1750, 2760]
})
sales_df
#plt plot을 따로 이용
plt.plot(sales_df['quarter'], sales_df['revenue'])

- 이걸 꾸며서 쓸 수도 있지만... 더 쉬운 방법이 있음
- df.plot() --> 알아서 숫자들을 선 그래프로 바꿔줌.
- 원래는 .plot(kind='line')을 해야 선 그래프지만, 너무 기본 디폴트 값이라서 그냥 .plot() 해도 됨.
sales_df.plot()
plt.show()
- 원하는 값으로 가로 세로를 정하고 싶으면 x='', y=''에 할당하면 됨.
sales_df.plot(x='quarter', y='revenue')
plt.show()
- plt import를 안하고 그냥 %matplotlib inline으로 바로 사용 가능함.
+ % 명령어 --> 매직 메소드
%matplotlib inline -> matplotlib 실행 후 코드 쉘 아래에 그래프 표기
%matpolotlib tk --> matpolotlib 실행 후 별도 창에 그래프가 나타남
%matplotlib inline
import pandas as pd
- 위 그래프들 예제랑 똑같은데, 1) 넣을 열들을 리스트로 받아올 수도 있음.
- 혹은 2) 보고 싶은 열들만 뽑아서 만든 dataframe에 바로 plot을 줄 수도 있음
- 아래 예제는 둘 다 정확히 같은 것임.
df.plot(y=['KBS', 'JTBC'])
df[['KBS', 'JTBC']].plot()
- 시리즈도 플롯 그릴 수 있음.
df['KBS'].plot()
<막대 그래프>
- 그래프 종류를 바꾸려면, 메소드가 바뀌는 plt와 달리 kind ='bar'만 바꾸면 됨.
sales_df.plot(x='quarter', y='revenue', kind='bar')
plt.show()
- 간단한 그래프는 x, y 안 써도 됨.
df.plot(kind='bar')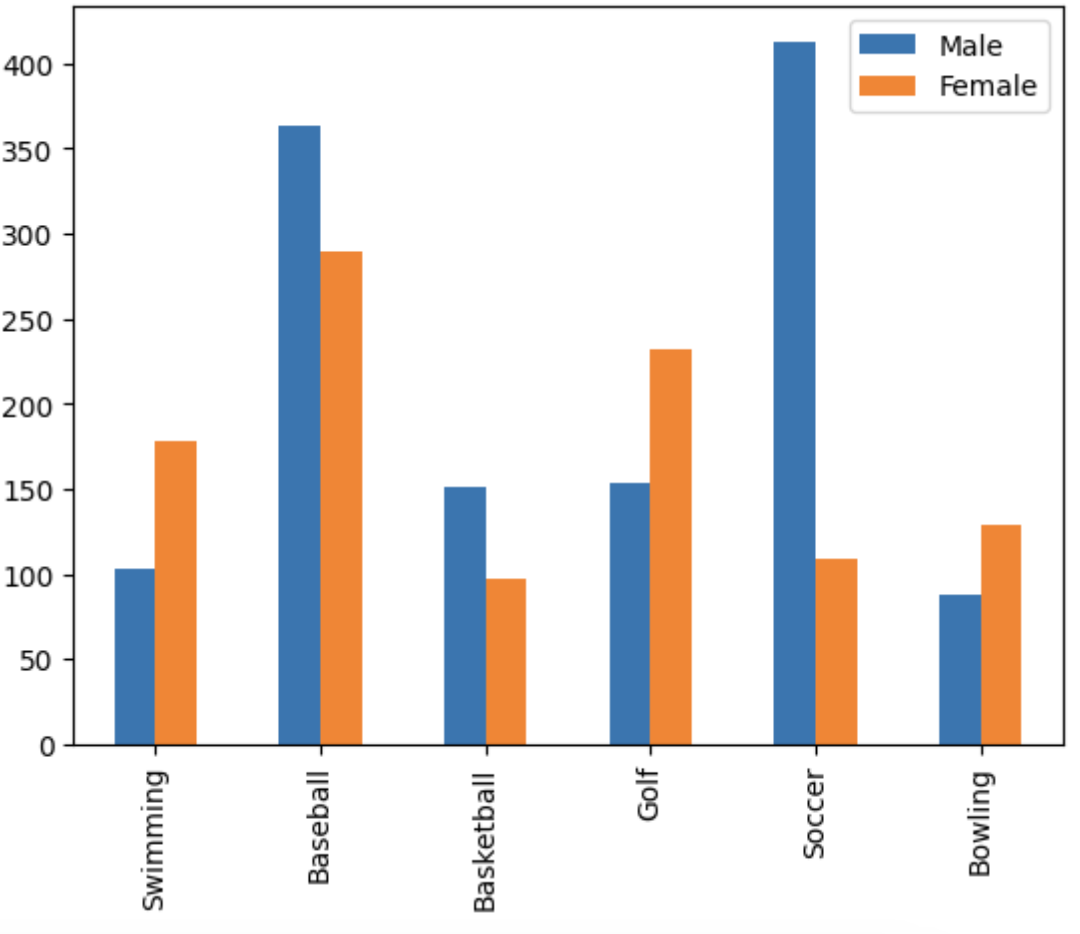
- 세로로 읽기가 힘들면 가로로 변경 가능함 kind='barh'
- horizontal
df.plot(kind='barh')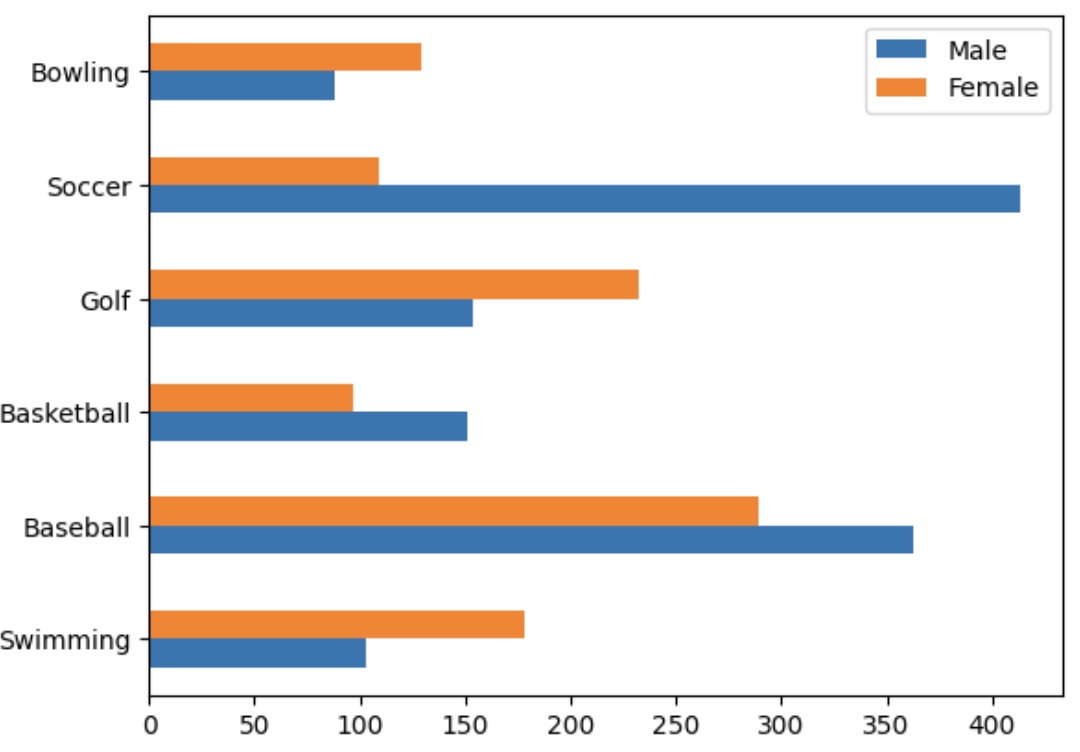
- 쌓아서 차이를 직접적으로 확인할 수도 있음. --> stacked = True
df.plot(kind='bar', stacked=True)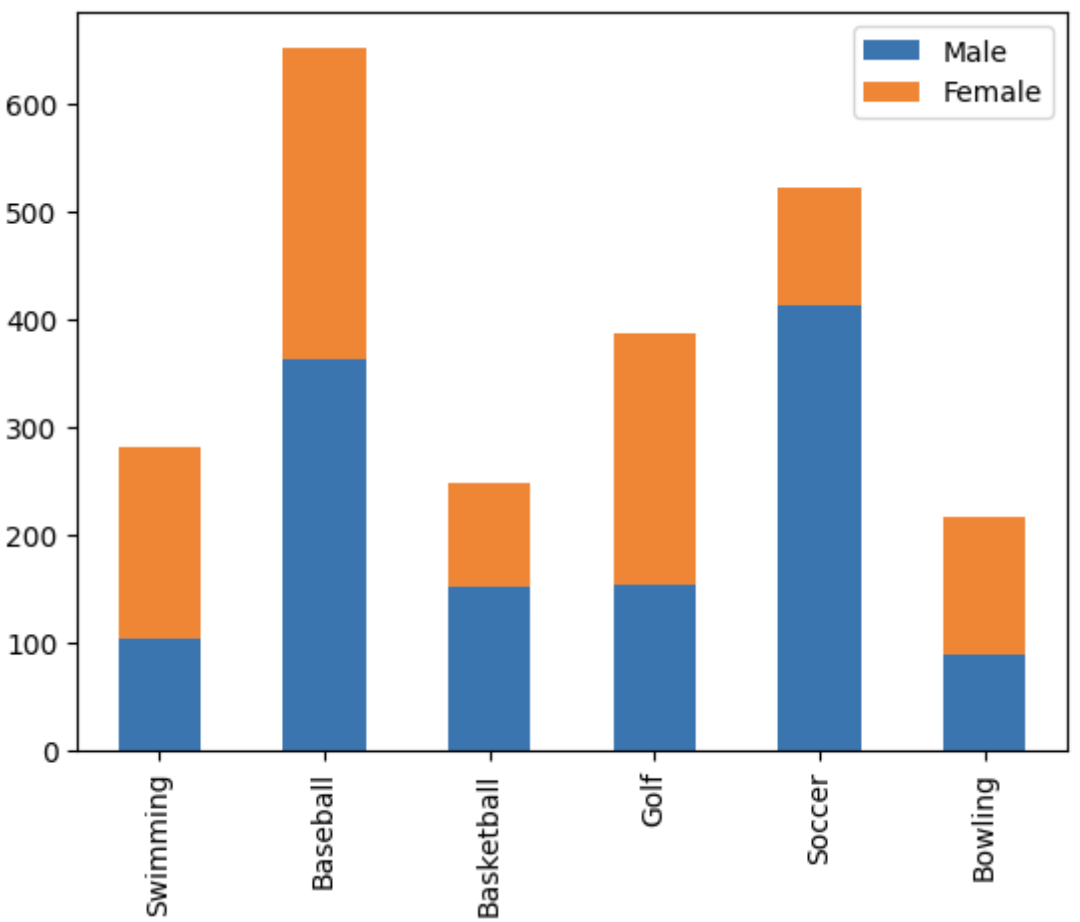
- 성별을 따로 보고 싶다면 필요한 것만 가지고 와서 만들면 됨.
df['Female'].plot(kind='bar')
<원 그래프/ 파이 차트>
- 비율을 확인하기 위함.
- kind='pie', labels = []를 붙여야 함.
sales_df.plot(y='revenue', kind='pie', labels = ['1Q', '2Q', '3Q', '4Q'])
plt.show()
- 그냥 시리즈를 떼 와서 만들 수 있음. --> 이러면 x, y 설정 안 해도 되서 편함
- %를 보이게 하려면 --> autopct='%1.1f%%'
df.loc[2017].plot(kind='pie', autopct='%1.1f%%')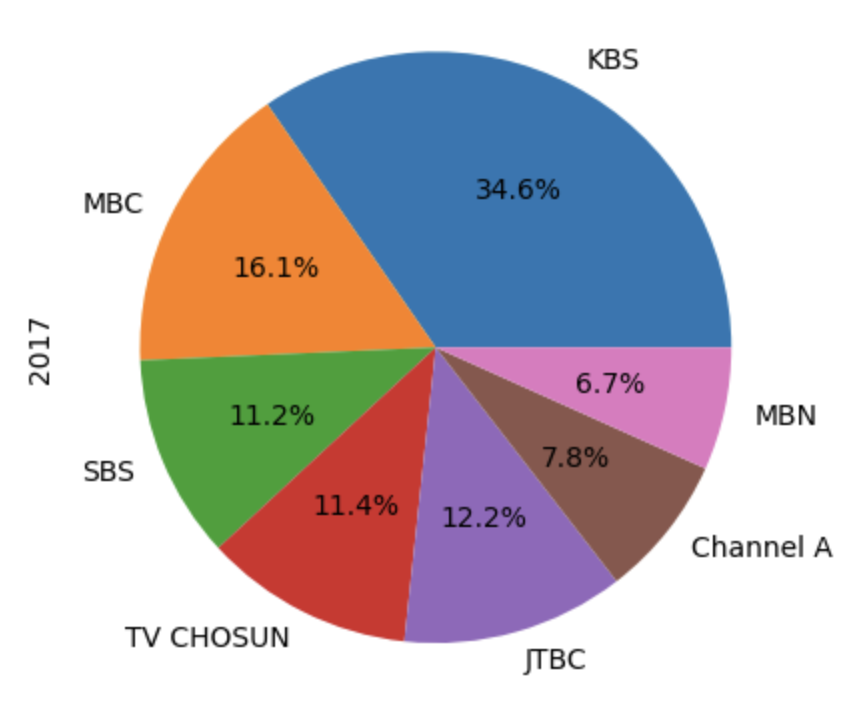
- 이외에도 디자인적 요소들이 있는데 아래 링크 확인해서 필요하면, 적용하면 됨.
https://matplotlib.org/stable/gallery/pie_and_polar_charts/pie_features.html
Pie charts — Matplotlib 3.9.0 documentation
Demo of plotting a pie chart. Swap label and autopct text positions Use the labeldistance and pctdistance parameters to position the labels and autopct text respectively. labeldistance and pctdistance are ratios of the radius; therefore they vary between 0
matplotlib.org
예제 1
- 조건에 맞는 코드를 냅다 짜기전에.. data를 잘 살펴 볼 것.
- 결과 값이 이상해서 나중에 확인해서 코드 추가하느라 시간이 너무 많이 감.
- 불린 인덱싱을 어떻게 활용할지도 고민을 많이 할 것.
- 나는 그냥 냅다.. mask 변수에 넣었는데 다른 사람이랑 공유할 것을 생각한다면, 따로 분리하는 게 나을 수도 condition은 여러 개 들어가도 상관이 없으니깐.
- pie 차트에서는 각 변수 명을 넣어주려면 .set.index('')를 써야 되고, y= '' 도 명시해 줘야 함.
%matplotlib inline
import pandas as pd
df = pd.read_csv('data/silicon_valley_details.csv')
mask_df = df[(df['company'] == 'Adobe') & (df['count'] > 0) &
(df['race'] == 'Overall_totals') &
(df['job_category'] != 'Totals') &
(df['job_category'] != 'Previous_totals') ]
mask_df.set_index('job_category').plot(kind='pie', y='count')
이거를 변수를 각각 쪼갠 것이 답이었음. -> 이러면 확실히 타인이 이해하기가 편해짐.
%matplotlib inline
import pandas as pd
df = pd.read_csv("data/silicon_valley_details.csv")
boolean_adobe = df['company'] == 'Adobe'
boolean_all_races = df['race'] == 'Overall_totals'
boolean_count = df['count'] != 0
boolean_job_category = (df['job_category'] != 'Totals') & (df['job_category'] != 'Previous_totals')
df_adobe = df[boolean_adobe & boolean_all_races & boolean_count & boolean_job_category]
df_adobe.set_index('job_category', inplace=True)
df_adobe.plot(kind='pie', y= 'count')<히스토그램>
- 각 값을 항목이 아닌 범위로 묶어서 항목으로 만드는 것.
++ 연속형 데이터는 히스토그램으로 보는 것이 편함 --> 키, 몸무게 등등
++ 이산형 데이터도 가능 --> 나이 같이
- kind = 'hist', y=''
- 기본 값은 bins = 10 으로 고정되어 있음. 원하는 만큼 값을 변경해서 추가 가능.
--> bins 가 많아진다고 좋은 그래프가 아님. 고민해서 선정할 것.
df.plot(kind='hist', y='Height')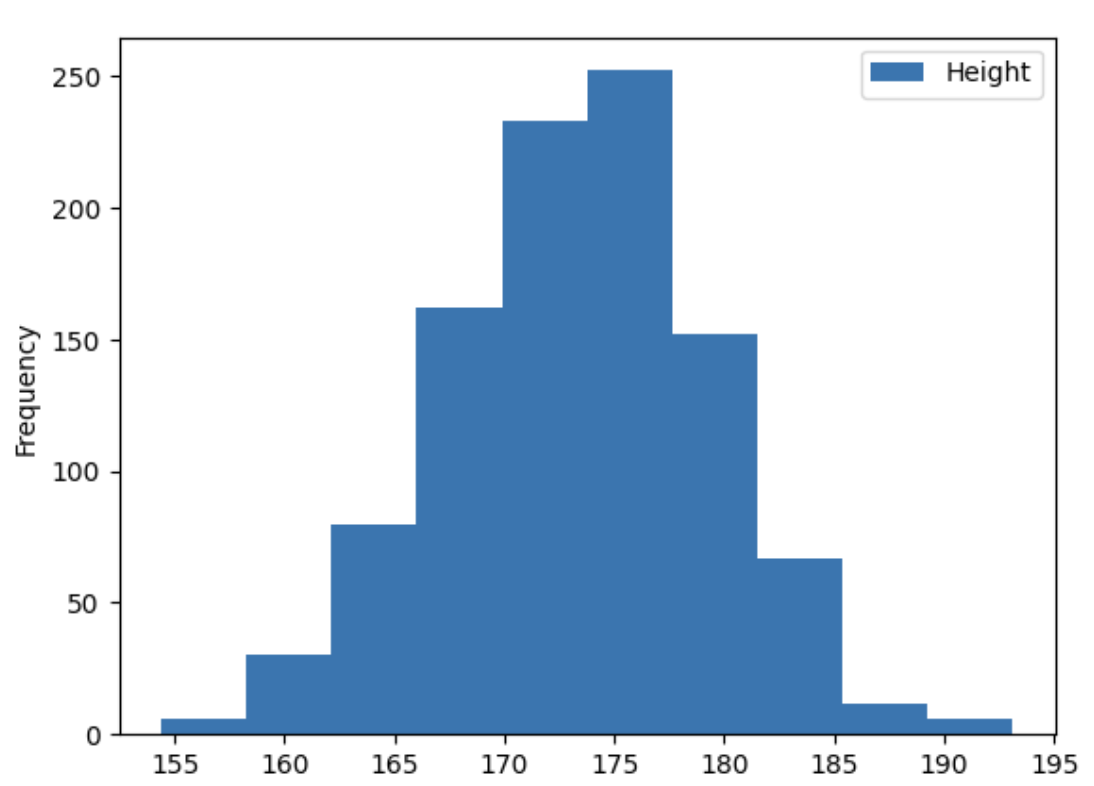
df.plot(kind='hist', y='Height', bins = 15)
+ 조건 식 응용해서 가지고 올 수 도 있음.
car_df.loc[car_df['manufacturer'] =='HYUNDAI', 'price'].plot(kind='hist', bins = 10)<Box Plot>
- box(가운데 박스) and whisker(콧수염, 양 끝 작대기 까지) plot



- IQR에 포함 되지 않는 것은 아웃라이어임.
- 분산이 넓은 지, 아웃라이어 제외하면 어디가 평균인지 등의 정보를 한 눈에 확인 가능.
++ 사분면의 값을 직접 구해볼 수도 있음
++ 컷오프 값이 궁금하다면 이렇게 하는 것도 좋을 듯
q1 = df['english_score'].quantile(0.25)
q3 = df['english_score'].quantile(0.75)
iqr = q3 - q1
q1 - 1.5 * iqr
#38.75
q3 + 1.5 * iqr
#88.75
- .describe()는 아웃라이어를 제외하지 않기 때문에 box plot의 결과 값이 조금 다를 수 있음.
- kind ='box' , y=''
#한 벡터
df.plot(kind='box', y='math score')
#여러 개
df.plot(kind='box', y=['math score', 'reading score', 'writing score'])
#그냥 y없이 해도 됨. df를 몇 개 불러오면
df[['math_score', 'science_score']].plot(kind='box')
plt.show()

--> 정보가가 많음, 데이터의 분포에 대한 값의 비교도 쉬움.
--> 박스 안에서도 밖에서도 이모조모 볼 수 있음.
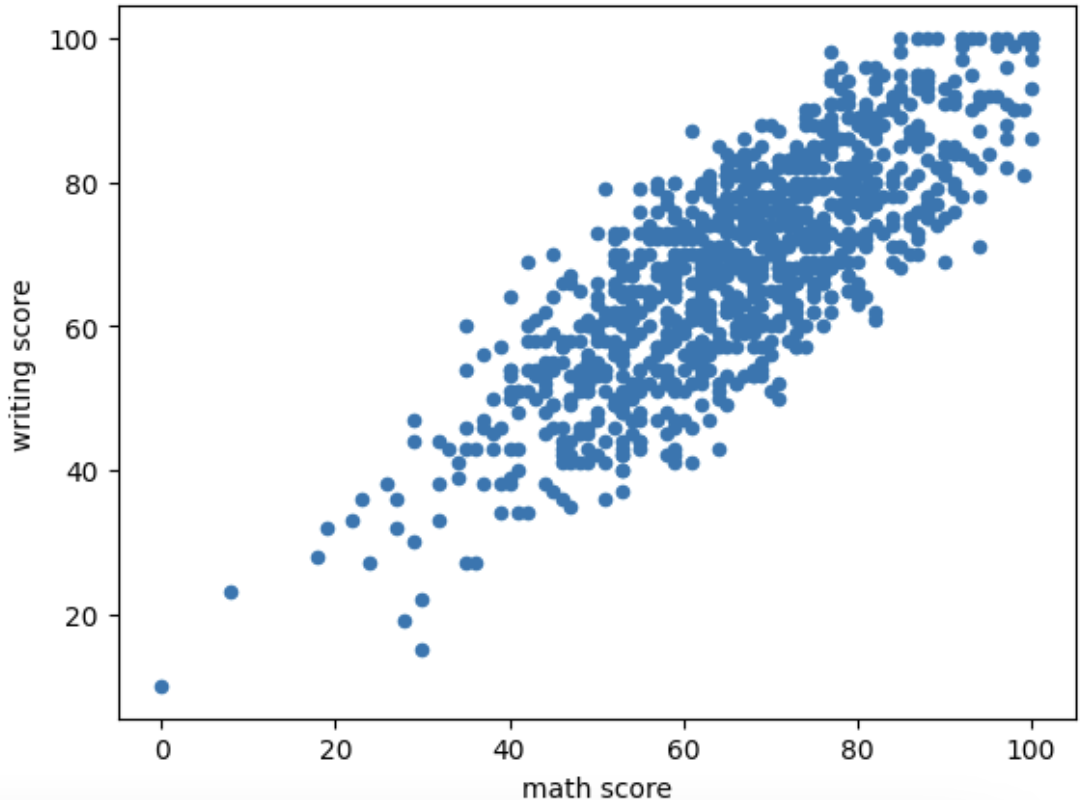
<산포도/산점도>
- 상관 점수를 보기 좋음.
- kind='scatter', x='', y=''
burger_df.plot(x='fat', y='calories', kind='scatter')
plt.show()
df.plot(kind='scatter', x='math score', y='writing score')
'Data Science > Statistics' 카테고리의 다른 글
| [기초 통계] 모집단과 표본, 기술통계와 추론 통계, 변수 종류, 데이터 분포 모양 (0) | 2024.06.11 |
|---|---|
| [Statistics] 군집 분석 cluster analysis, sns.clustermap() (3) | 2024.06.05 |
| [Statistics] 상관 계수, .corr(), scatterplot(), regplot(), sns.heatmap() (0) | 2024.06.02 |
| [Statistics] mean, median, Q1, Q3, outlier, mode, .describe() (3) | 2024.06.02 |
| [Statistics] PDF 확률 밀도 함수, KDE kernel Density Estimation (0) | 2024.06.01 |