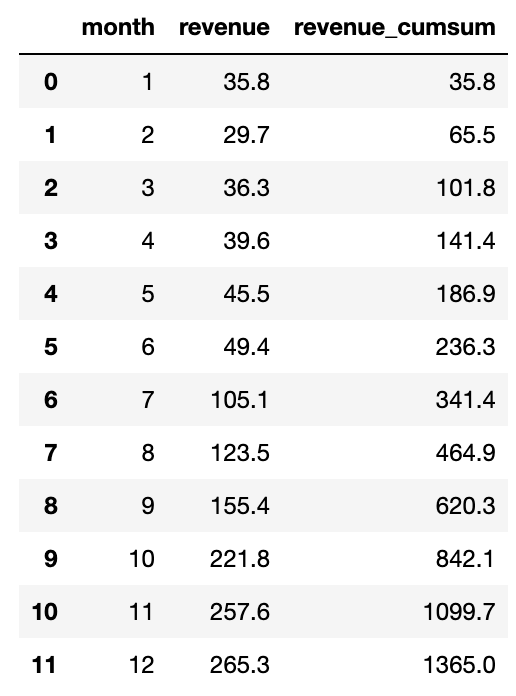
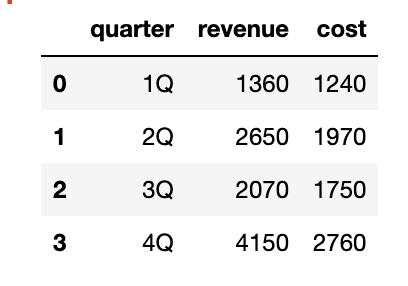
# 코드잇 데이터 사이언스 강의 듣는 중 - . cumsum() --> cumulative sum 누적 합- 예를 들어, 수입의 누적 값을 확인하고 싶을 때 등에 쓸 수 있음. df['revenue_cumsum']= df['revenue'].cumsum()df - 진짜.. 너무 편한듯.. ㅎ - 플롯으로 변경 추이를 한 눈에 확인할 수도 있음. df.plot(x='month', y='revenue_cumsum') df.plot(x='month', y='revenue_cumsum', kind='bar') - . cumprod() --> cumulative product 누적 곱- 예를 들어, 연간 금리에 따른 만기액 같은 계산이 가능해짐. +..ㅎ 내가 진짜 학생 때 제일 싫어했던....