728x90
반응형
# 코드잇 데이터 사이언스 강의 듣는 중
<군집 분석 cluster analysis>
- 서로 관련이 있는 집단들을 묶어서 분석하는 것
- sns.clustermap()
- 강의에서는 상관이 있는 것들을 묶는 예제를 보여줬는데,
실제로는, 상관.... 보다는 변수들 간의 관계나 값의 분포 차이에 따라서 군집을 나눔.
+ 군집분석은 data driven 이기 때문에 일반화 하기가 어렵다는 문제가 있지만,
확진적 요인 분석 CFA 과 잠재 프로파일분석 LPA으로 논문을 썼기 때문에 흥미로운 결과를 많이 뽑아낼 수 있다고 생각하는 편이다.
- 필요한 칼럼만 분리하고.
interests = df.loc[:, 'History':'Pets']
interests.head()
- 상관을 아예 변수에 넣음.
corr = interests.corr()
corr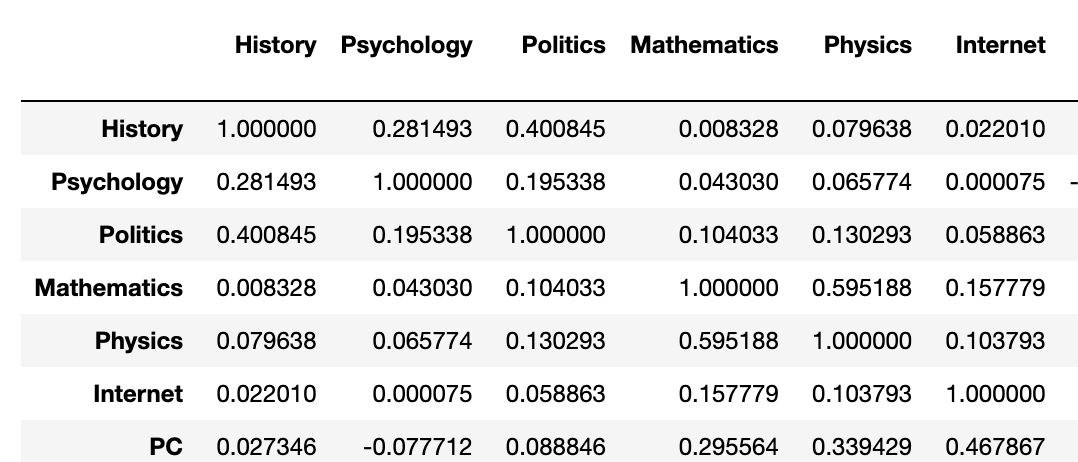
- 역사와 관련된 과목들끼리 묶고자 sort를 할 수도 있지만
corr['History'].sort_values(ascending=False)
- 시각화해서 맵형태로 볼 수도 있음
sns.clustermap(corr)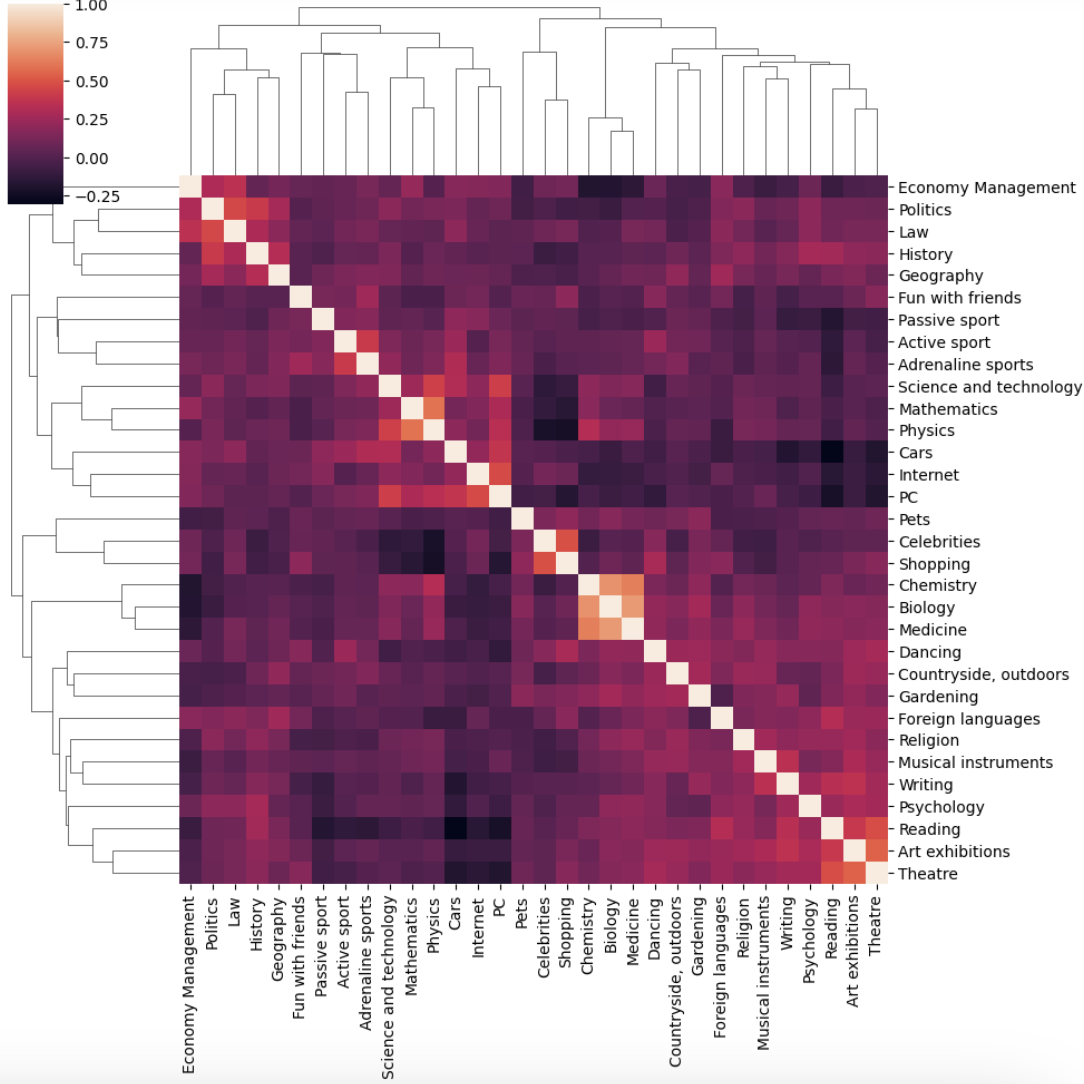
- 묶인 연관성을 볼 수 있긴 하지만, ..... 난......이거 별로....선 그래프나 스캐터로 묶인 집단이 더 예쁜데...ㅎ
728x90
반응형
'Statistics' 카테고리의 다른 글
| [기초통계] 분산과 표준편차 (2) | 2024.06.11 |
|---|---|
| [기초 통계] 모집단과 표본, 기술통계와 추론 통계, 변수 종류, 데이터 분포 모양 (0) | 2024.06.11 |
| [Statistics] 상관 계수, .corr(), scatterplot(), regplot(), sns.heatmap() (0) | 2024.06.02 |
| [Statistics] mean, median, Q1, Q3, outlier, mode, .describe() (2) | 2024.06.02 |
| [Statistics] PDF 확률 밀도 함수, KDE kernel Density Estimation (0) | 2024.06.01 |