# 코드잇 데이터 사이언스 강의 듣는 중
<EDA, Exploaratory Data Analysis>
- data set을 탐색적으로 살펴보면서 일반적인 패턴을 확인하는 것으로, 데이터 분석의 첫 단계.
- row, column의 의미나, 분포, 연관성 등을 다양한 각도에서 확인하는 것.
- 공식이 따로 있는 것이 아니라 데이터를 살펴보는 모든 것을 의미함.
- 대개 시각적 기법을 가장 많이 사용함.
++ 즉, 데이터 분석의 초기 단계로,
패턴, 이상치와 관례 등 기술적 통계부터 시각화를 사용해서 확인하는 것을 의미함.
- 데이터의 특성과, 이후 분석과 가설 검정에 대한 정보를 제공함.
- 그니깐 약간 말그대로 탐색적임.
- 가설 검정 전 단계에 이걸로 뭘 할 수 있을 지 고민하는 단계임.
=> 그러니깐 기본적으로 표본이 어떤 지.. 결측지는 어떤지, 어디로 치우친 값인 지를 전반적으로 확인하며 다음 연구의 방향을 정하는 것.
근데...어차피 연구 전에 가설을 이미 세워놓지 않나..?
심리 연구들은 대부분은 실험적 연구는 하지 않고, 가설을 다 세운 상태에서 연구하는 것이라서
데이터 셋의 특성이 연구의 방향을 결정하지는 않았다.
뭐.. 원론적인 것이긴 하고, 연구자나 연구 분야에 따라서 자율성이 있기도 했지만, 적어도 임상은 ...아니 나는 선호하지 않는다.
약간, 가설 없이 일단 돌려본다는..
신경과학 연구에 가까운 느낌..?
나오면 한다..?
근데 이런 식으로 하면, 논의에서 망함. ㅎ
가설을 세우고, 왜 그게 기각인지
왜 이 데이터 셋에서는 그렇게 하는 게 문제가 되는 지를 살피는 게 더 타당할 것으로 보임.
이 단계를 EDA라고 따로 부르는 지조차.. 몰랐음.
너무나 당연한 단계고, 일반적으로 기술통계 값을 확인하는 것은. ...그냥 진짜 당연하니깐.
어쨌든 이전 강의에서 해온 던대로,
1) .head()로 데이터 상태 확인,
2) .describe() 눈에 띄는 것들 보기
3) 이 때 표본 특성(인구통계학적 특성) 확인하기(예, 대학생들 위주인가 등)
4) 숫자로 되어있지 않은 칼럼들은 .value_counts()로 각각 분포 값 확인해줄 것.
5) 필요하다면 플롯그려서 대략적인 값의 분포 확인하기.
#인구 통계학적 정보 빼오기
basic_info = df.iloc[:, 140:]
basic_info.head()
# 기본 통계값 확인
basic_info.describe()
#str 칼럼들 따로 n수 확인
basic_info['Gender'].value_counts()
basic_info['Handedness'].value_counts()
basic_info['Education'].value_counts()
#필요하다면 플롯으로 전반적 분포 확인
sns.violinplot(data=basic_info, y='Age')
sns.violinplot(data=basic_info, x='Gender', y='Age')
sns.violinplot(data=basic_info,x='Gender', y='Age', hue='Handedness')

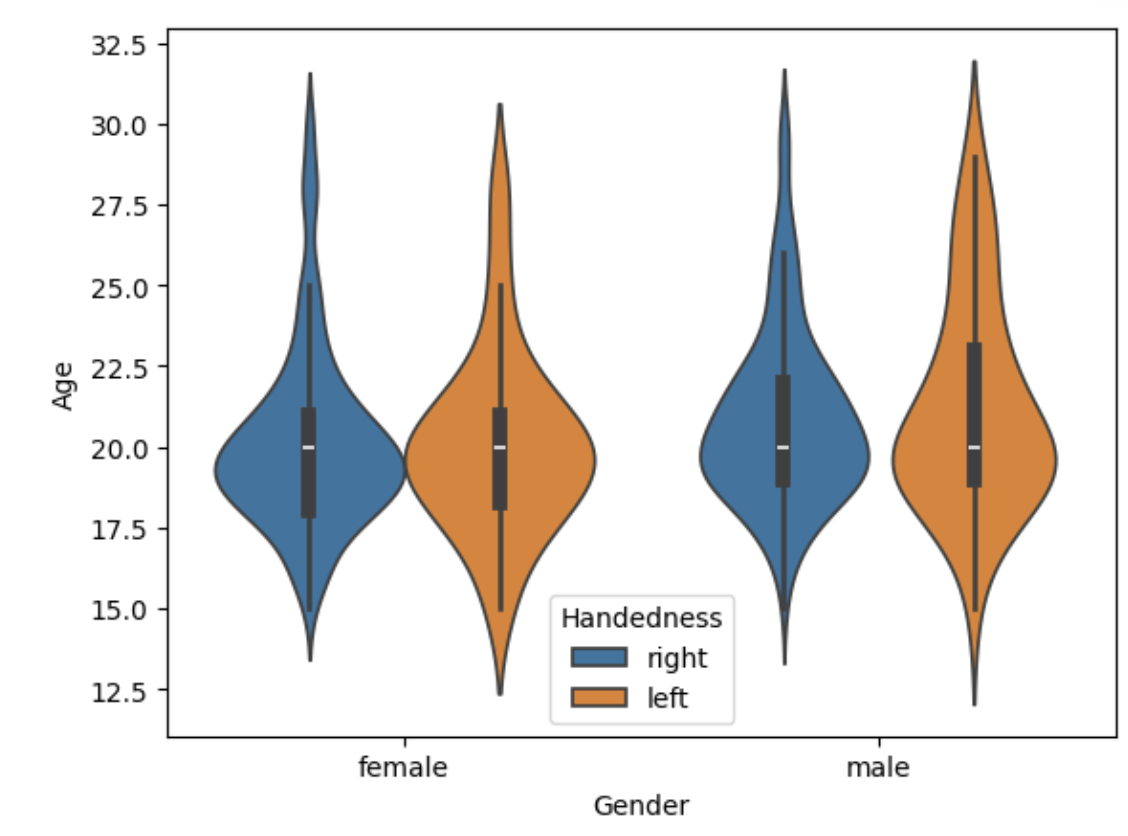
- 이미 앞서 본 내용이기에 한 번에 결과값을 순서대로 넣었다.
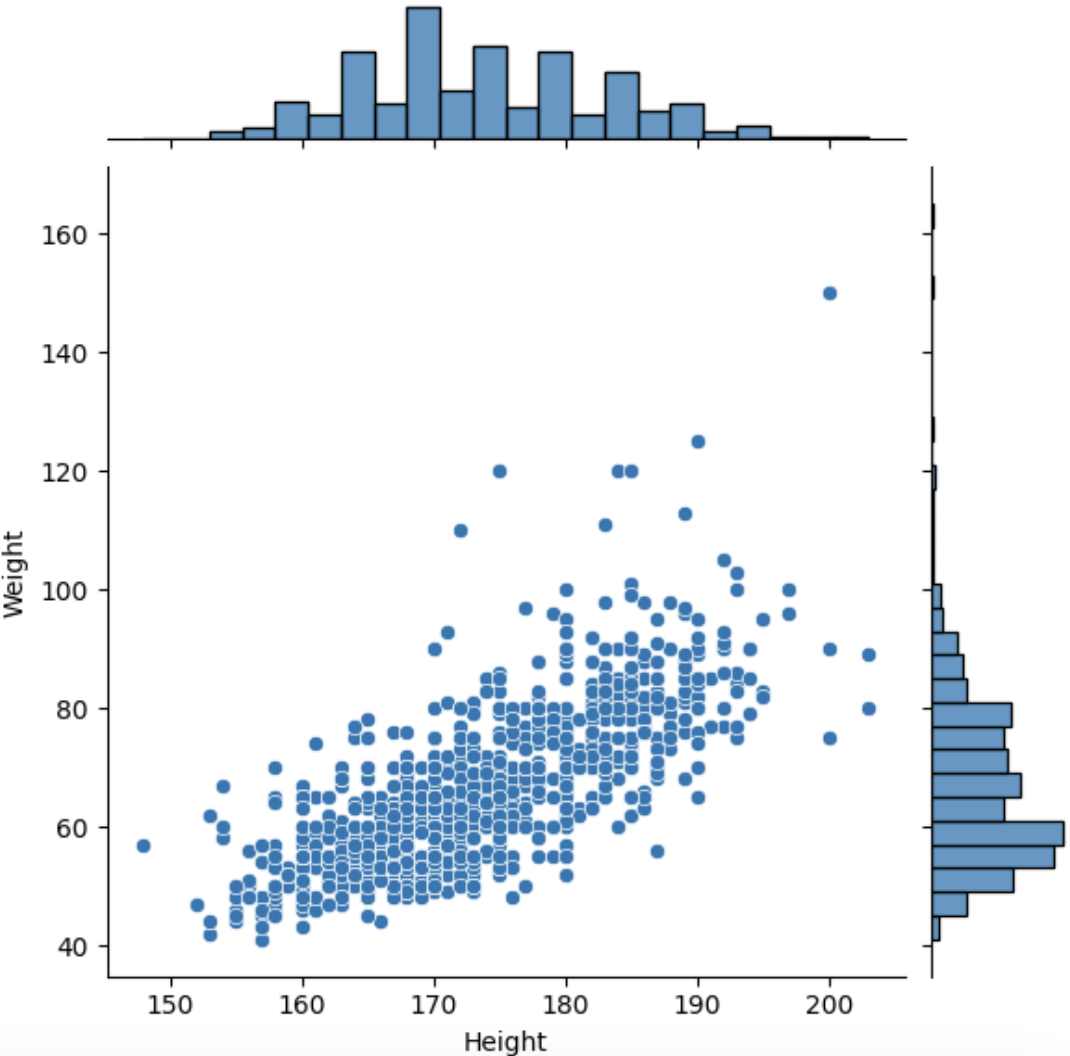
<joint plot>
- 이건 처음 본 건데 histogram + scatter 가 조인트 되어 있음.
- 재밌게 생기고 정보가는 많은 데 지면을 많이 차지함 ㅎ
- .jointplot(data=, x='', y='')
예제1
- 나는 sort를 안 썼는데, 해설은 써서 까먹을까봐 같이 올려둠.
df.loc[df['gender'] == 'M','occupation'].value_counts()
#men = df[df['gender'] == 'M']
#men['occupation'].value_counts().sort_values(ascending=False)
++ pandas 버전 확인
import pandas as pd
pd.__version__
#'2.2.1'
++ 데이터 중간에 안 끊기고 보이게 하는 방법
- pandas 가 보여주는 로와 벡터 열의 수를 조정해주면 됨.
- pd.options.display.max_rows = 값은 필요한 만큼 넣어주면 됨.
pd.options.display.max_rows=100
pd.options.display.max_columns = 50https://pandas.pydata.org/pandas-docs/stable/user_guide/options.html
Options and settings — pandas 2.2.2 documentation
Warning Enabling this option will affect the performance for printing of DataFrame and Series (about 2 times slower). Use only when it is actually required. Some East Asian countries use Unicode characters whose width corresponds to two Latin characters. I
pandas.pydata.org
'Data Science > Pandas' 카테고리의 다른 글
| [EDA] 값 추가, 문자열 필터링 .str.contains(''), 값 분리, .str.split() (0) | 2024.06.07 |
|---|---|
| [EDA] 적용 예제 (0) | 2024.06.07 |
| [Pandas] boolean indexing 불린 인덱싱, 다중 조건 인덱싱 (0) | 2024.05.31 |
| [Pandas] DataFrame/Series 정보 확인, .describe(), .value_counts() (0) | 2024.05.30 |
| [Pandas] DataFrame 값 수정/추가/삭제, header/index 명 지정하기 (0) | 2024.05.28 |