#코드잇 데이터 사이언스 강의 듣는 중
<데이터 값 바꾸기>
- 데이터를 바꾸려면 이름 지정하고 = 바꿀 값 넣어주면 됨.
- [] 로 여러 값들 변경이 가능.
- 한 값으로 여러 값들을 통일 할 경우 []에 갯수 맞춰서 하나씩 넣어도 되지만, 그보다는 리스트 밖으로 빼주면 더 간단함.
iphone_df.loc['iPhone 8', '메모리'] = '2.5GB'
#행 한 줄 전부 변경
iphone_df.loc['iPhone 8'] = ['2016-06-31', '5.5', '4GB', 'iOS 11.0', 'No']
# 같은 값으로 변경
iphone_df['디스플레이'] = '5.2 in'
#iphone_df['디스플레이'] = ['4.7 in', '4.7 in','4.7 in','4.7 in','4.7 in','4.7 in','4.7 in']
#여러 벡터 동시에 변경
iphone_df[['디스플레이', 'Face ID']] = 'x'
#로도 마찬가지
iphone_df.loc[['iPhone 7', 'iPhone X']] ='o'
#슬라이싱도 같음
iphone_df.loc['iPhone 7':'iPhone X'] ='o'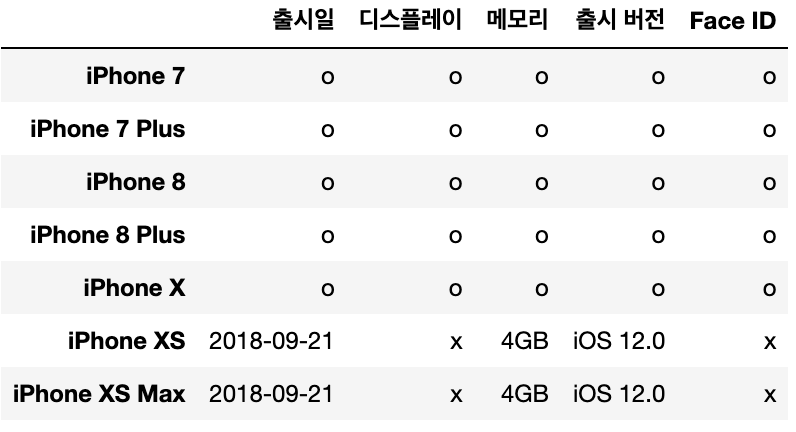
- 조건문으로 가지고 올 수 있고, 마찬가지로 한 값으로 변경 가능
iphone_df.loc[iphone_df['디스플레이'] > 5] = 'p'
iphone_df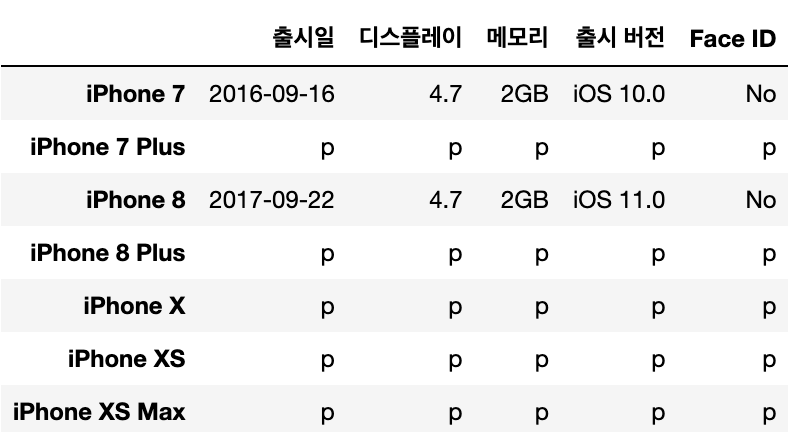
+ 다만 동시에 변경이 되면서 갑자기 타입 에러가 뜰 수 있는데, 이 때는 이미 변경되었을 수 있으니,
df 값 확인해보고 df.dtypes 로 정확히 알아 볼 것.
++ 추가로 플로트로 타입 변경하는 법 (파이썬으로 그냥.. 냅다 하면.. 안됨.. 다른 언어랑 다 섞임.
- 2개 방법 있음.
# .astype()
df['column_name'] = df['column_name'].astype(float)
# .to_numeric()
df['column_name'] = pd.to_numeric(df['column_name'])
- 위치로도 가지고 올 수 있음.
- 제발 헷갈리지 말 것 [[앞쪽 = 로우], [뒤쪽 = 벡터] ] --> 그 안에 몇 개가 있건 위치로 보는 것.
예. iphone_df.iloc[[1, 3], [1,4]] --> 로우 1, 3번의 벡터 1,4번을 각각 가지고 오는 것.
iphone_df.iloc[[1, 3], [1,4]] = 'v'
iphone_df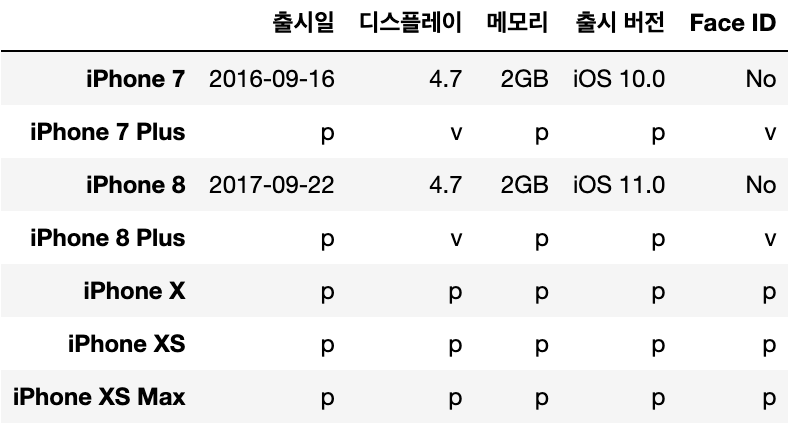
<데이터 값 추가하기>
- data frame에 값을 추가하려면, 그냥 변수 명을 치고 = 값을 넣어주면 됨.
--> 즉, 기존에 없는 칼럼 명이면 데이터를 추가하는 것이고, 기존에 있는 변수 명이면 값을 수정 하는 것.
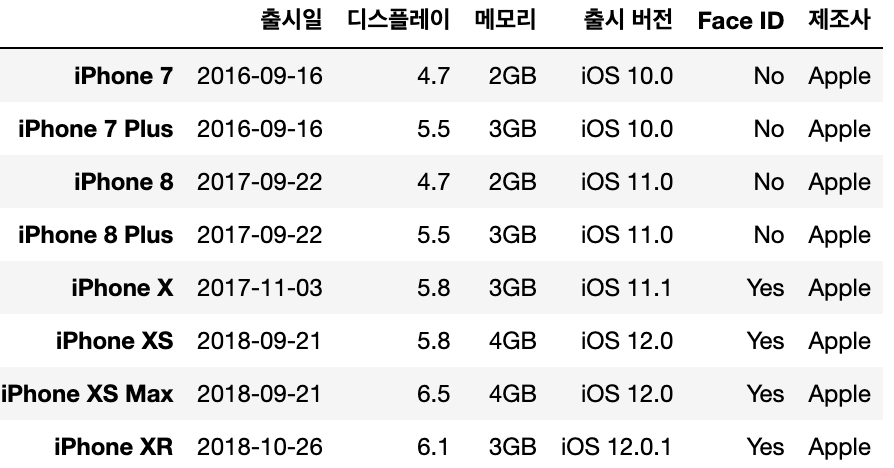
#행
iphone_df.loc['iPhone XR'] = ['2018-10-26', 6.1, '3GB', 'iOS 12.0.1', 'Yes']
#열
iphone_df['제조사'] = 'Apple'
<데이터 값 삭제하기>
- 삭제하려면, .drop('변수 명')
- 필요에 따라서 axis = 'index/columns', inplace=True/False를 추가해주면 됨.
- axis= 'index' or 0 --> 로우를 뜻 함
- axis = columns or 1--> 벡터
- inplace= False
--> 로 데이터를 변경하는 게 아니라 이번 데이터 프레임에서만 삭제 됨을 의미함. 계속 쓰고 싶다면 변수 지정하면 됨.
--> True로 하면, 로 데이터를 변경해줌.
iphone_df.drop('iPhone XR', axis= 'index', inplace= False)
iphone_df.drop('제조사', axis= 'columns', inplace= True)
- axis를 따로 써주지 않아도 바로 columns = '칼럼명' 넣어줘도 충분함.
--> 디폴트 값이 index 즉 로우 값을 삭제하는 것이기 때문
loan_df.drop(columns='married')
#같음
loan_df.drop('married', axis=1)
+ inplace 대신 값에 다시 넣어줘도 됨.
loan_df = loan_df.drop(columns='married')
- 여러 개는 리스트에 넣어서 한 번에 삭제하면 됨.
iphone_df.drop(['iPhone 7', 'iPhone 8', 'iPhone X'], axis= 'index', inplace= True)
<index로 지정하기>
- .set_index() --> 특정 벡터를 인덱스로 지정 가능.
loan_df.set_index('loan_id')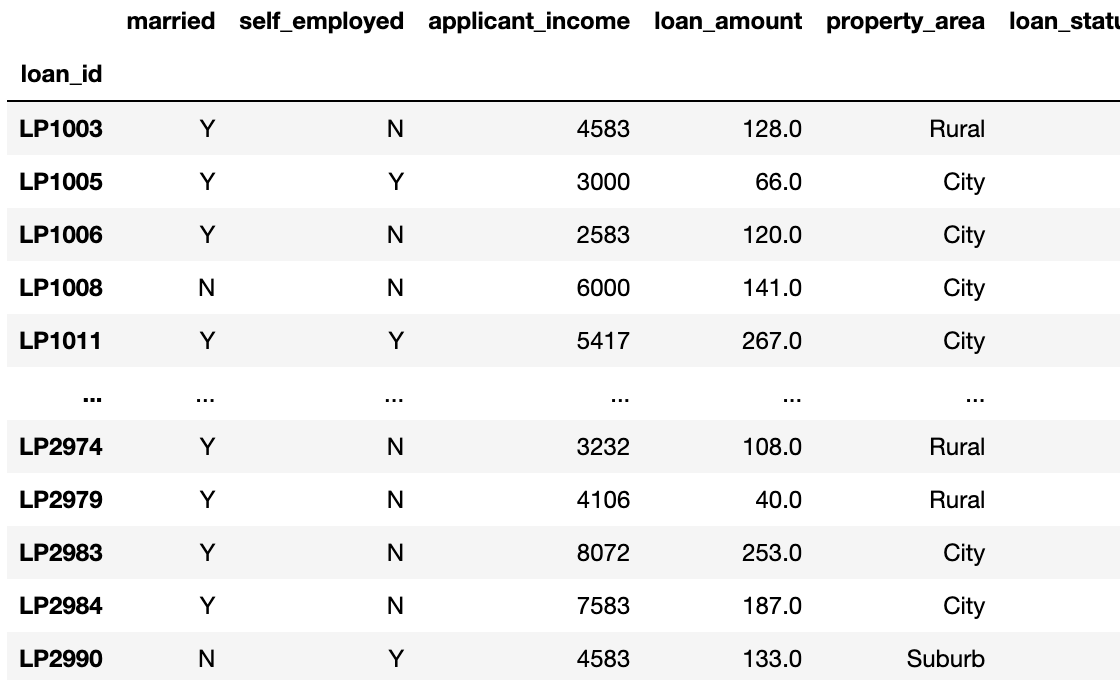
- but, 재실행 하면, 다시 이전으로 돌아감.
- 변경 사항을 그대로 유지하게 하려면 1) 원래의 변수에 다시 넣어줘야 함.
loan_df = loan_df.set_index('loan_id')
- 다시 되돌리려면, .reset_index()를 해주면 됨.
loan_df.reset_index()
- 혹은 2) inplace = True 를 추가할 것.
liverpool_df.set_index('Number', inplace = True)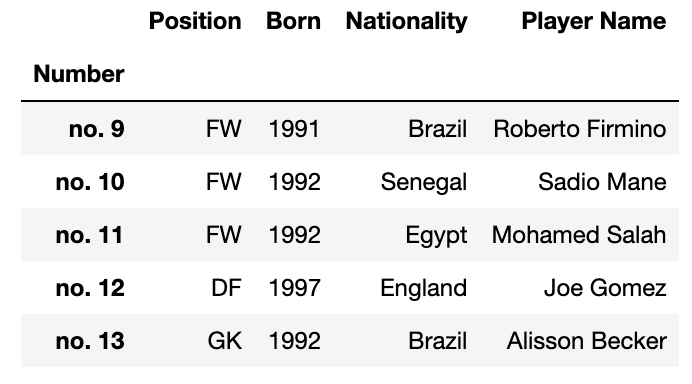
++ 리뉴얼 강의에서는 inplace 설명을 안 하시고, 계속 원래 변수에 넣어줌..
왜 그러는 것임?
<header 명 변경하기 / index 명 추가하기>
- header 명 변경하기 .rename()
- python dictionary 사용.
- index 명을 추가 할 수 있음. .index.name
# 한 개만 변경
liverpool_df.rename(columns = {'position' : 'Position'}, inplace = True)
# 여러 개도 그냥 변경하면 됨
liverpool_df.rename(columns = {'position' : 'Position', 'born' : 'Born', 'number':'Number', 'nationality':'Nationality'}, inplace = True)
#이걸 따로 변수로 넣어줘도 됨
new_columns = {'married_or not' :' married', 'self_employed or not': 'self_employed', 'applicant_income': 'income', 'loan_amount':'amount'}
loan_df.rename(columns=new_columns)
#인덱스 명 추가
liverpool_df.index.name = 'Player Name'
- index로 지정하기 --> .set_index()
--> 그 전에 기존 값을 칼럼에 추가해줘야 함. 안 그러면 밀려서 기존 인덱스가 사라짐.
liverpool_df.index --> 위에서 이미 지정되어 있는 값을 새로운 칼럼으로 추가해서 넣어줌.
liverpool_df['Player Name'] = liverpool_df.index

++ 인덱스는 겹칠 일이 없는 것으로 사용하는 것이 좋음.
이 경우는 이름은 우연히 겹칠 수도 있기 때문에 등 번호가 best
+++ .reset_index()를 사용하면, 자연스럽게 기존의 인덱스가 뒤로 빠지지만,
행 번호가 맨 앞에 생기기 때문에 행 번호 필요없으면 따로 처리해 줘야 함.
liverpool_df.reset_index('Number')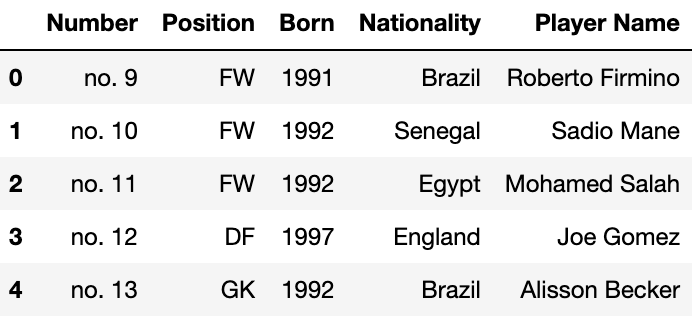
<칼럼 type 변경하기 >
- .astype('')
loan_df['income'].astype('float')
--> int(정수), float(실수), object(문자형) 등 으로 원하는 형태로 변경해주면 됨.
'Data Science > Pandas' 카테고리의 다른 글
| [Pandas] boolean indexing 불린 인덱싱, 다중 조건 인덱싱 (0) | 2024.05.31 |
|---|---|
| [Pandas] DataFrame/Series 정보 확인, .describe(), .value_counts() (0) | 2024.05.30 |
| [Pandas] DataFrame indexing 문법 정리 (이름, 위치) (1) | 2024.05.27 |
| [Pandas] 인덱싱 indexing, 슬라이싱 slicing, 필터링 filtering (0) | 2024.05.26 |
| [Pandas] numpy와 pandas 비교, pd.DataFrame(), header 변경 (0) | 2024.05.20 |