#코드잇 데이터 사이언스 강의 듣는 중
- 판다스는 기본적으로 넘파이를 바탕으로 만들어서 발전시킨 것
--> 외부 데이터 읽고 쓰기, 정리된 데이터 새로운 파일에 저장, 데이터 시각화 가능
--> 넘파이보다 표 형식을 다루는 것에 능함. 넘파이는 복잡한 수학 연산을 할 때 사용.
- Pandas DataFrame: 2차원 형태의 데이터를 다루기 위한 자료형
- Pandas Series: 1차원 형태의 데이터를 다루기 위한 자료형 --> dataframe은 사실상 여러 개의 series로 구성된 것.
- 열: column --> 데이터의 특징
- 행: row/index --> 레코드 (각각에 대한 정보)
| Numpy Array | Pandas DataFrame |
| - 인덱스 값(숫자)로 칼럼을 표현 - 2차원 넘파이 배열은 모든 값이 같은 자료형이어야 함 |
- 칼럼에 변수 명 입력이 가능하고 그 값으로 찾을 수 있음. - 다양한 자료형을 한 번에 담을 수 있음. |
- 2차원 행렬은 행마다 []로 끊어서 입력하면 되고, 데이터 타입은 숫자는 int64고 문자형을 object라고 함.
- 걍.. 객체로 전체를 의미하는 거 같은데.. 굳이 또 문자형이 object라고 해서 뭐지 싶음.
++ 아래 나와.. 헷갈리지 않게 .. 주의
- 여러 타입을 넣을 수 있지만 같은 칼럼에서는 같은 자료형이어야만 함.
import pandas as pd
two_dimentional_list = [['tasha', 50, 86], ['lynn', 89, 31], ['ben', 68, 91],['nico', 88,75]]
# columns와 index에 값을 넣어주면 됨.
my_df = pd.DataFrame(two_dimentional_list, columns = ['name', 'english_score', ',math_score'], index = ['a','b','c','d'])
my_df
type(my_df)
#pandas.core.frame.DataFrame
my_df.index
#Index(['a', 'b', 'c', 'd'], dtype='object')
my_df.dtypes
#name object
english_score int64
,math_score int64
dtype: object
- pandas .Series([])는 기본적으로 일차원 배열인데, 일반적인 np.array()나 python 리스트와의 차이점은
컬럼이나 로우에 변수 명을 집어 넣을 수 있다는 것임.
- 사실 pd.DataFrame() 안에 들어갈 값은
1. python list
2. numpy array
3. pandas Series
모두 다 가능. 즉 어떻게 만들어주느냐의 차이일 뿐
import numpy as np
import pandas as pd
two_dimensional_list = [['dongwook', 50, 86], ['sineui', 89, 31], ['ikjoong', 68, 91], ['yoonsoo', 88, 75]]
two_dimensional_array = np.array(two_dimensional_list)
list_of_series = [
pd.Series(['dongwook', 50, 86]),
pd.Series(['sineui', 89, 31]),
pd.Series(['ikjoong', 68, 91]),
pd.Series(['yoonsoo', 88, 75])
]
# 아래 셋은 모두 동일합니다
df1 = pd.DataFrame(two_dimensional_list)
df2 = pd.DataFrame(two_dimensional_array)
df3 = pd.DataFrame(list_of_series)
print(df1)
#칼럼과 로를 지정하지 않았기 때문
# 0 1 2
#0 dongwook 50 86
#1 sineui 89 31
#2 ikjoong 68 91
#3 yoonsoo 88 75
- 데이터 프레임을 만들 때 칼럼 이름을 설정하지 않아서 그냥 인덱스 값이 나오는 것.
- 데이터 프레임을 만들 때 columns = ['']로 이름을 추가해 줄 수 있음.
list_df = pd.DataFrame(two_dimensional_list, columns=['name', 'english_score', 'math_score'])
array_df = pd.DataFrame(two_dimensional_array, columns=['name', 'english_score', 'math_score'])
- 사실 어차피 2차원 배열로 표를 만들어 내는 것이기 때문에 파이썬 사전으로 넣어주면 더 편한 듯
- 처음부터 key랑 value값으로 칼럼과 로가 구분되고 인덱스를 추가할 때도 편함.
- 여전히 3개 다 들어갈 수 있음.
import numpy as np
import pandas as pd
names = ['dongwook', 'sineui', 'ikjoong', 'yoonsoo']
english_scores = [50, 89, 68, 88]
math_scores = [86, 31, 91, 75]
dict1 = {
'name': names,
'english_score': english_scores,
'math_score': math_scores
}
dict2 = {
'name': np.array(names),
'english_score': np.array(english_scores),
'math_score': np.array(math_scores)
}
dict3 = {
'name': pd.Series(names),
'english_score': pd.Series(english_scores),
'math_score': pd.Series(math_scores)
}
# 아래 셋은 모두 동일합니다
df1 = pd.DataFrame(dict1)
df2 = pd.DataFrame(dict2)
df3 = pd.DataFrame(dict3)
print(df1)
# name english_score math_score
#0 dongwook 50 86
#1 sineui 89 31
#2 ikjoong 68 91
#3 yoonsoo 88 75
- 파이썬 사전이 담긴 리스트는 오히려 편함.
- 이미 다 지정되어 있기 때문에, pd.DataFram()에 넣어주기만 하면 됨.
import numpy as np
import pandas as pd
my_list = [
{'name': 'dongwook', 'english_score': 50, 'math_score': 86},
{'name': 'sineui', 'english_score': 89, 'math_score': 31},
{'name': 'ikjoong', 'english_score': 68, 'math_score': 91},
{'name': 'yoonsoo', 'english_score': 88, 'math_score': 75}
]
df = pd.DataFrame(my_list)
print(df)
# english_score math_score name
#0 50 86 dongwook
#1 89 31 sineui
#2 68 91 ikjoong
#3 88 75 yoonsoo
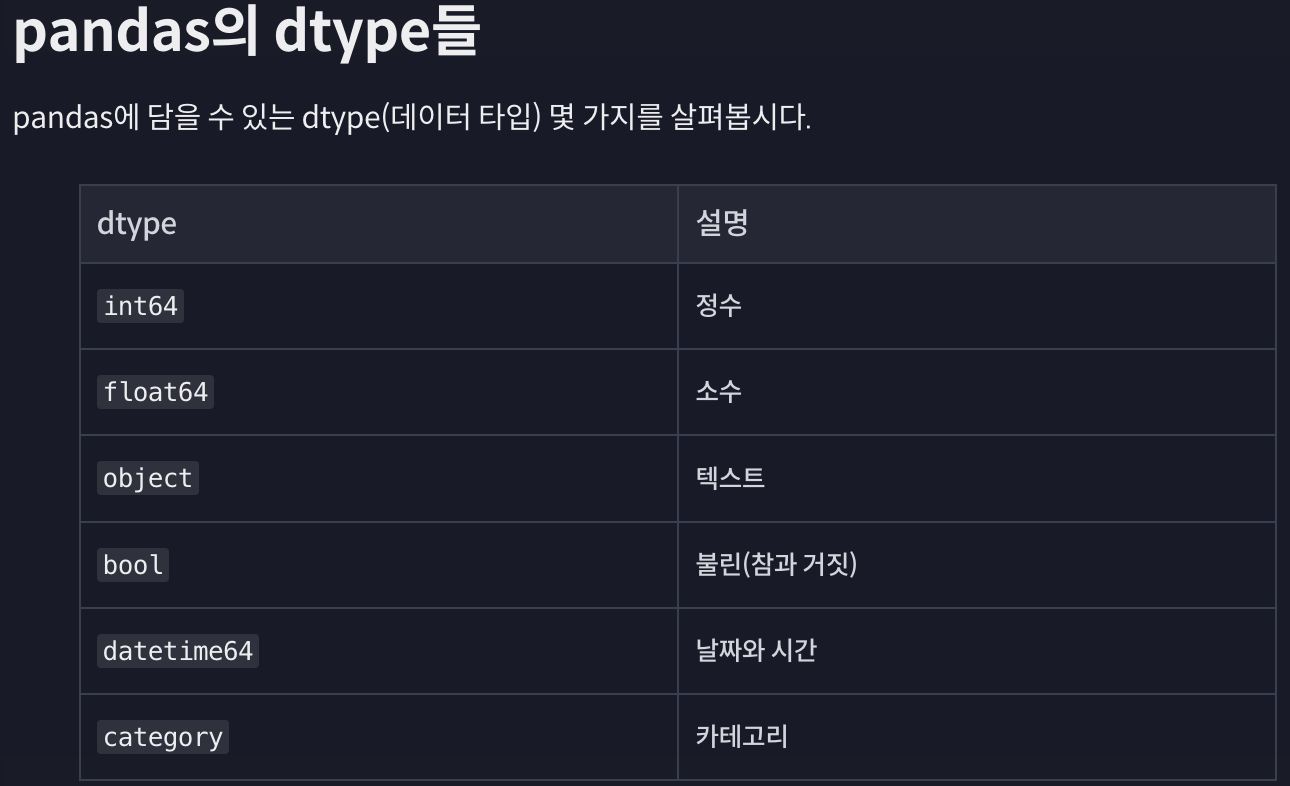
- 확인은 .dtypes()로 가능
- csv 파일 읽어올 수 있는데.. 현재 running 중인 파일과 같은 폴더에 있어야지만 가능.
- 처음에 안 넣어놔서 ... jupyter 상의 ui로 편하게 넣으려고 했으나 이동이 안됨 ㅡ ㅡ
++ 코드는 따로 정리
- 헤더
import pandas as pd
iphone_df = pd.read_csv('codeit/data/iphone.csv')
iphone_df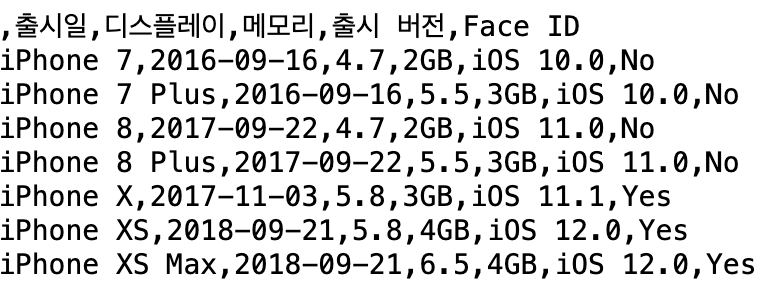

근데 만약에 header가 없는 경우에는 아래 값을 맘대로 읽어 오기 때문에,
- heder = None 을 추가해줘야 함.
- 변수명 추가하려면, names =[''] --> 칼럼 수에 맞춰서 넣어주면 됨.
iphone_df = pd.read_csv('codeit/data/iphone.csv', header = None)
iphone_df = pd.read_csv('codeit/data/iphone.csv', header = None,
names = ['출시일', '디스플레이', '메모리', '출시 버전', 'Face ID'])
- 맨 처음 헤더 값은 비어있는데 로도 비워 놓은 상태임.
- 걍 로를 첫 칼럼 자체로 만들어 줄 수도 있음. --> index_col=0
- 인덱스 칼럼을 0으로 하면, 아래처럼 첫 벡터가 그 자체로 로가 됨.
--> 이거 진짜 너무 유용함... ㅎ
=> 파일을 읽어 들일 때 특정 column을 인덱스로 지정하고 싶으면, index_col 파라미터를 쓰면 됨.
=> 칼럼 명이 있다면, 그걸 가지고 와도 됨( index_col = '디스플레이')
=> 즉 상품명이 0번 column인 가장 왼쪽에 있으니까, index_col=0임
iphone_df = pd.read_csv('codeit/data/iphone.csv', index_col=0)
'Data Science > Pandas' 카테고리의 다른 글
| [Pandas] boolean indexing 불린 인덱싱, 다중 조건 인덱싱 (0) | 2024.05.31 |
|---|---|
| [Pandas] DataFrame/Series 정보 확인, .describe(), .value_counts() (0) | 2024.05.30 |
| [Pandas] DataFrame 값 수정/추가/삭제, header/index 명 지정하기 (0) | 2024.05.28 |
| [Pandas] DataFrame indexing 문법 정리 (이름, 위치) (1) | 2024.05.27 |
| [Pandas] 인덱싱 indexing, 슬라이싱 slicing, 필터링 filtering (0) | 2024.05.26 |