# 코드잇 데이터 사이언스 강의 듣는 중
<Data Frame 정보 확인>
- 대용량 데이터의 경우 불러와서 다 보기에는 값이 너무 많을 수도 있음.
- 맨 윗 줄부터 선택한 갯수(n) 보기 --> .head(n)
- 맨 아랫 줄부터 선택한 갯수(n) 보기 --> .tail(n)
#위부터
laptops_df.head(3)
#아래부터
laptops_df.tail(6)
- 데이터 행 렬 크기 확인 --> .shape
- 칼럼 종류 확인 --> .columns
- 칼럼 정보 확인 --> .info()
- 칼럼 간 기초통계 확인 --> .describe()
#크기 확인
laptops_df.shape
#(167, 14)
#(로우 개수, 칼럼 개수)
#칼럼 종류 확인
laptops_df.columns
#데이터 타입 확인
df.dtypes
#칼럼 정보 확인
laptops_df.info()
#칼럼 간의 기초 통계 확인
laptops_df.describe()
++ .describe() --> 함수, 메소드
++ .shape --> 속성
=> 객체지향 프로그래밍 강의도.. 듣쟈 ^^
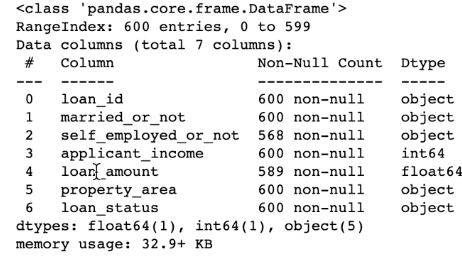
--> .info()를 통해서 결측치를 확인할 수 있음.
--> non null이 2, 4 벡터는 다른 벡터와 동일 하지 않아서, 결측치들이 있는 것을 알 수 있음
loan_df.describe(include='all')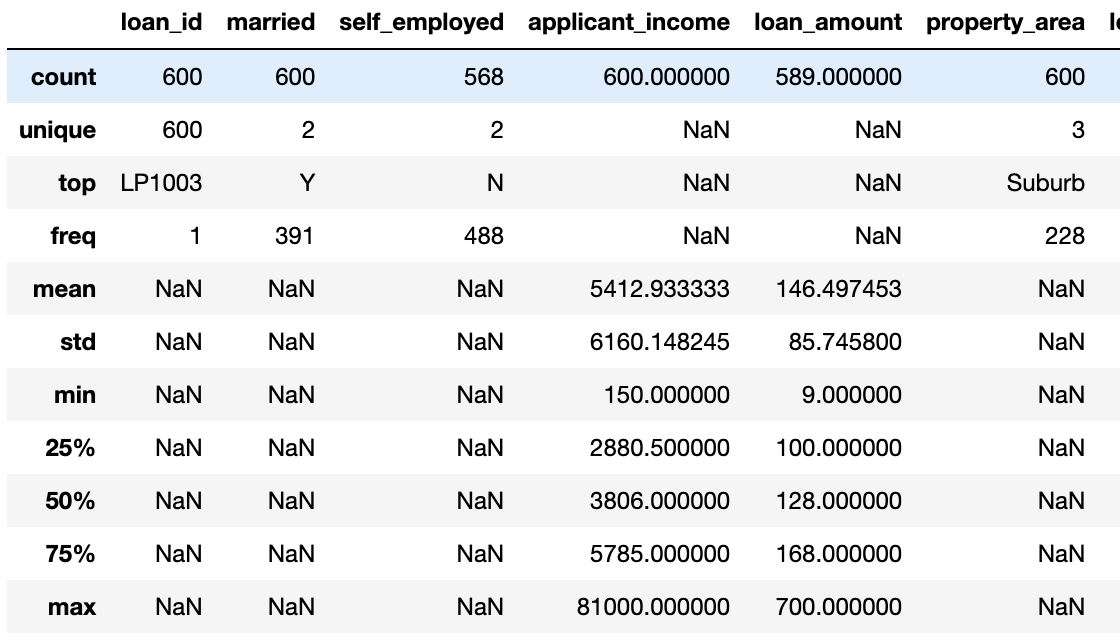
--> 문자열 값도 포함되게 한 눈에 볼 수 있음.
- 행을 선택한 벡터의 기준대로 정렬할 수 있음. --> .sort_values(by = '')
- 기본적으로 숫자는 작은 것부터 큰 순으로 정렬되는 데 순서를 바꾸고 싶으면 --> ascending = False
- 새로운 dataframe 말고 로 데이터를 바꾸고 싶으면 --> inplace = True
laptops_df.sort_values(by='price', ascending = False, inplace= True)
<Series 정보 확인>
- numpy array와 series는 비슷하지만, 시리즈는 변수 명(헤더)가 있지만, 넘파이는 없음.
- dataframe에서 쓰는 메소드와 다른 것들이 있기 때문에 서로가 안 쓰는 것을 쓰려고 하면 에러가 뜸
- so, 해당하는 메소드나 속성을 쓸 것.
#예시
df.unique()
#AttributeError: 'DataFrame' object has no attribute 'unique'
laptops_df['brand']
#데이터 타입 확인
loan_df['amount'].dtype
#중복 값 제외하고 보기
laptops_df['brand'].unique()
#각 칼럼당 항목 확인
laptops_df['brand'].value_counts()
#칼럼 개수 확인
laptops_df['brand'].value_counts().shape
#시리즈 정보 확인 => count, unique, top(자주 나오는 것)과 그 freq(빈도)
laptops_df['brand'].describe()
- 숫자형 데이터의 .describe()
loan_df['amount'].describe()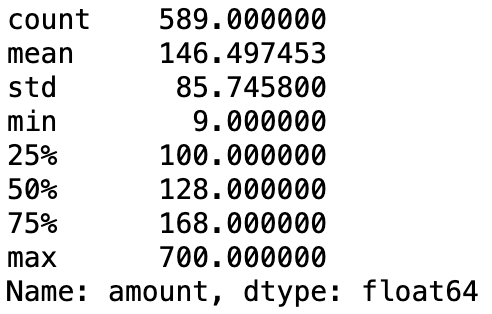
--> df.랑 같고, 우리가 아는 형태임.
[문자형]
- 숫자형이랑 결과 값이 다름.
-.describe()
#문자형
loan_df['self_employed'].dtype
#dtype('O')
loan_df['self_employed'].describe()
--> 다른 정보가 나옴.
- .unique()
loan_df['self_employed'].unique()
- .value_counts()
loan_df['self_employed'].value_counts()
--> unique() 에서 확인되었던 nan이 안 보임.
--> 별도의 매개변수를 넣어줘야함.
- dropna = False
loan_df['self_employed'].value_counts(dropna=False)
--> nan 갯수도 포함되어서 나타남.
- normalize = True
loan_df['self_employed'].value_counts(dropna=False, normalize=True)
--> 각 값들의 분포 확인 가능.
--> N이 약 81% 차지함.
<Series 를 dataframe으로 출력 가능>
- 시리즈와 데이터 프레임은 다른 형태지만, 둘 다로 표현 가능
- df.[['벡터', '벡터']] 는 벡터 리스트를 불러올 때 쓰지만, 브라켓 [[]]을 시리즈에 겹쳐주면 dataframe으로 출력됨
#시리즈 출력
loan_df['amount']
#데이터 프레임 출력
loan_df[['amount']]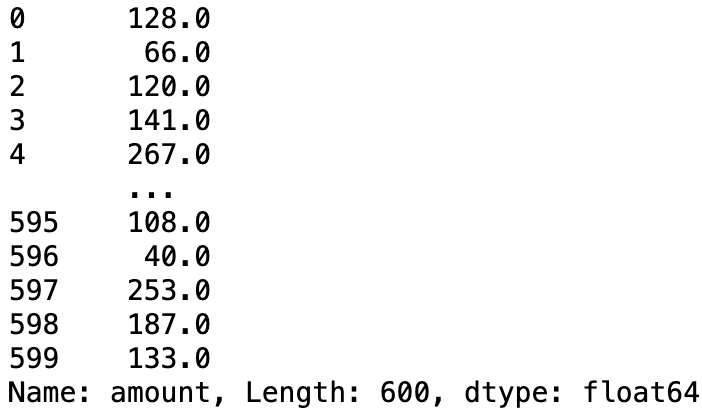
--> 시리즈 출력

--> 데이터 프레임으로 출력 가능.
--> so, 필요에 따라서 혹은 쓰고 싶은 메소드나 속성에 따라서 원하는 대로 출력하면 될듯
<예제>
- 예시1
- 변수로 안 만들고 단순히 condition 변수로만 만들어서 계산할 수 있지만,
나중에 쓸 수도 있으니깐 유의미한 값(예, 밀도)은 우선 변수로 만들어 둘 것.
wc_df['density'] = wc_df['Population']/wc_df['Land area (in sqKm)']
df_high_density = wc_df[wc_df['density'] > 10000]
df_high_density.info()
density_ranks =wc_df.sort_values(by = 'density', ascending = False)
density_ranks['City / Urban area']
- 예시2
..ㅎ 값을 새로 추출하면 기존 data와 인덱스가 달라지는 것을 반드시 염두할 것..
- 그래서 중복 같아도 만든 변수에서 해당 값을 확인해야 함.. ㅎ
- 너무 헤맸어.. 진짜... 값 4가 있는 것을 못 찾겠어서 = 하나만 써서.. 자꾸 4로 바꿔서
노가다로.. .head(20)해서 값을 찾았음... 너무 어리석은 방법임..ㅎ
#만약 도시가 4개인 국가를 찾는 경우
country_city_counts =wc_df['Country'].value_counts()
country_city_counts[country_city_counts ==4]
#한 번에 하려면 좀 복잡해도 이렇게 쓸 수도 있음. 었쨌든 인덱스가 기존 값과 다른 것을 기억할 것.
#df['Country'].value_counts()[df['Country'].value_counts() == 4]
#이것은 노가다임..ㅎ
#country_city_counts[:20]
++ 도시와의 교집합을 확인하려고 하지 말고, 그냥 country에서 여러 번 나오면 그게 도시가 여러 곳이 있는 곳임. 컴퓨터적으로 생각하자...
- 예시 3
- 이게.. 3번째 조건이 내가 알고 있는 코드 선에서는 쓸 수가 없었음..
- 원래는 위에서 했던 대로 course_counts[course_counts < 5]로 끝내려고 했는데 ... 이 값이 boolean이 아닌 series라고 all_con에 적용이 안되서.. 지피티에게 몇 번 물어보다가 최대한 모르는 메소드가 적은 방법으로 정착했음..
- all_con을 not allowed 할당하는 것까진 생각했는데 != 값을 allowed 할당하는 것이 아니라 처음부터 그렇게 만들고 해당 값만 바꾸는 방향으로 생각하지 못한 것이 아쉬움.
ver1
import pandas as pd
df = pd.read_csv('data/enrolment_1.csv')
con1 = (df['course name'] =='information technology') & (df['year'] == 1)
con2 = (df['course name'] =='commerce') & (df['year'] == 4)
course_counts = df['course name'].value_counts()
con3 = df['course name'].isin(course_counts[course_counts < 5].index)
all_con = con1 | con2 | con3
df['status'] = 'allowed'
df.loc[all_con, 'status'] = 'not allowed'
df
- .isin() --> Series 또는 DataFrame의 각 요소가 특정 값 리스트에 포함되는지 여부를 불리언 값으로 반환함.
- .index --> DataFrame 또는 Series의 인덱스(행 레이블)를 반환하거나 설정할 때 사용 (접근하거나 변경할 때)
.. .map()은 일단 패스 ..(+ 아래에 있음)
- 해설은 for문을 사용했는데.. 더 복잡해 보임.. 조건도 다 나눠서 했음.
ver2 해설
import pandas as pd
df = pd.read_csv('data/enrolment_1.csv')
df["status"] = "allowed"
# 조건 1
boolean1 = df["course name"] == "information technology"
boolean2 = df["year"] == 1
df.loc[boolean1 & boolean2, "status"] = "not allowed"
# 조건 2
boolean3= df["course name"] == "commerce"
boolean4= df["year"] == 4
df.loc[boolean3& boolean4, "status"] = "not allowed"
# 조건 3
allowed = df["status"] == "allowed"
course_counts = df.loc[allowed, "course name"].value_counts()
closed_courses = list(course_counts[course_counts < 5].index)
for course in closed_courses:
df.loc[df["course name"] == course, "status"] = "not allowed"
# 테스트 코드
df
- 해설 코드를 보면 df["status"]를 먼저 정의함. 1, 2는 같고 3은.. list로 만들어서 for문으로 하나씩 할당했음.
- for문으로 이렇게 할 수 있다고 익히면 될 듯. 템플릿으로 기억하면 될 듯.
- 예시 4
- ㅎ 결국 .map()을 쓰게 됨.
- .map() --> 1) ()안에 함수를 넣어주거나, 2) 앞의 벡터 뒤에 조건식 값 더해 넣을 때 그 위치를 잡기 위함. 진짜 mapping ; 그냥 뒤에 붙여 넣어주는 것으로 이해
- 함수 적용:
- .map()을 사용하여 시리즈의 각 요소에 함수를 적용할 수 있습니다.
- 사전 또는 시리즈를 이용한 값 치환:
- .map()을 사용하여 사전이나 다른 시리즈를 기반으로 값을 매핑
- 일단 내가 처음으로 짠 코드이고.. 답은 for문일 것 같으니, elif 고민해볼 것임.
ver1
import pandas as pd
df = pd.read_csv('data/enrolment_2.csv')
course_count = df['course name'].value_counts()
df['room assignment'] = 'Auditorium'
con2 = (df['course name'].map(course_count) >= 40) & (df['course name'].map(course_count) < 80)
con3 = (df['course name'].map(course_count) >= 15) & (df['course name'].map(course_count) < 40)
con4 = (df['course name'].map(course_count) >= 5) & (df['course name'].map(course_count) < 15)
con5 = df['status'] == 'not allowed'
df.loc[con2, 'room assignment'] = 'Large room'
df.loc[con3, 'room assignment'] = 'Medium room'
df.loc[con4, 'room assignment'] = 'Small room'
df.loc[con5, 'room assignment'] = 'not assigned'
df
- if 조건문 생각하면서 짠 코드는 이건데......해설과 매우 비껴감...
- 처음엔 이전 해설대로 allowed = df["status"] == "allowed"
course_counts = df.loc[allowed, "course name"].value_counts() 이렇게 해보려고 했지만,, for문을 만든 과정에서 지피티가 지움.
- for문도 인자를 2개 넣어서 만들고.. 아예 course_counts에다가 .items() 붙여서 딕셔너리(키:밸류)로 만들었음.
- 그렇게..ㅎ .item()도 알게 되었음.. ㅎ
+ .items() --> 파이썬 딕셔너리와 판다스 시리즈에서 .items() 메서드는 시리즈의 인덱스-값 쌍을 튜플로 반환하는 이터레이터를 제공함.
- 메서드는 딕셔너리와 시리즈 객체의 모든 항목에 쉽게 접근하고 반복할 수 있게 함.
import pandas as pd
# 예제 데이터프레임 생성
data = {'course name': ['Math', 'Physics', 'Chemistry', 'Math', 'Math', 'Physics'],
'status': ['allowed', 'allowed', 'not allowed', 'allowed', 'allowed', 'allowed']}
df = pd.DataFrame(data)
# 각 코스별 학생 수 계산
course_counts = df['course name'].value_counts()
# .items() 사용하여 반복
for course, count in course_counts.items():
print(f"Course: {course}, Count: {count}")
#Course: Math, Count: 3
#Course: Physics, Count: 2
#Course: Chemistry, Count: 1ver2
import pandas as pd
df = pd.read_csv('data/enrolment_2.csv')
df['room assignment'] = 'Auditorium'
course_counts = df['course name'].value_counts()
for course, count in course_counts.items():
if 40 <= count < 80:
df.loc[df['course name'] == course,'room assignment'] = 'Large room'
elif 15 <= count < 40:
df.loc[df['course name'] == course,'room assignment'] = 'Medium room'
elif 5 <= count < 15:
df.loc[df['course name'] == course,'room assignment'] = 'Small room'
df.loc[(df['status'] == 'not allowed'), 'room assignment'] = 'not assigned'
df
- 파이썬은 조건문 그냥 저렇게 이어서 쓸 수 있음. 다른 언어랑 달리.
- 해설은.. 또 굉장히 달라짐..ㅎ
1) 일단 수강인원을... course name이 아닌 status에서 allowed 된 얘들한테서 가지고 옴.
2) 각 조건에 따라 강의실 규모별 과목 리스트를 따로 만들어줌.. 이걸 어케 해야 할지 고민하다가.. 걍 내 식대로 한 거였는데..
3) not allowed 그대로 활용해서 not assignment 할당해줌. 그러니깐.. 이전 것을 활용하는 능력인 것인가?
4) for문을 써서 각 리스트 별로 강의실 크기를 다시 할당해줌..
ver3 해설
import pandas as pd
df = pd.read_csv('data/enrolment_2.csv')
# 과목별 인원 가져오기
allowed = df["status"] == "allowed"
course_counts = df.loc[allowed, "course name"].value_counts()
# 각 강의실 규모에 해당되는 과목 리스트 만들기
auditorium_list = list(course_counts[course_counts >= 80].index)
large_room_list = list(course_counts[(80 > course_counts) & (course_counts >= 40)].index)
medium_room_list = list(course_counts[(40 > course_counts) & (course_counts >= 15)].index)
small_room_list = list(course_counts[(15 > course_counts) & (course_counts > 4)].index)
# not allowed 과목에 대해 값 지정해주기
not_allowed = df["status"] == "not allowed"
df.loc[not_allowed, "room assignment"] = "not assigned"
# allowed 과목에 대해 값 지정해주기
for course in auditorium_list:
df.loc[(df["course name"] == course) & allowed, "room assignment"] = "Auditorium"
for course in large_room_list:
df.loc[(df["course name"] == course) & allowed, "room assignment"] = "Large room"
for course in medium_room_list:
df.loc[(df["course name"] == course) & allowed, "room assignment"] = "Medium room"
for course in small_room_list:
df.loc[(df["course name"] == course) & allowed, "room assignment"] = "Small room"
# 정답 출력
df
- 예시 4
... 사실 이거 도저히 모르겠어서 포기했음..
- 해설 보니깐 앞에서 한 리스트를 그대로 가지고 와서 하던데 ,, 그렇게 말고 room assignment에서 못 가지고 오려나.. 고민하다가 코드가 도저히 안되서 .. 포기함.
--> 강의 리뉴얼 됬다고 하니깐 다시 들으면서 고민해야 겠음
import pandas as pd
df = pd.read_csv('data/enrolment_3.csv')
# 과목별 인원 가져오기
allowed = df["status"] == "allowed"
course_counts = df.loc[allowed, "course name"].value_counts()
# 각 강의실 규모에 해당되는 과목 리스트 만들기
auditorium_list = list(course_counts[course_counts >= 80].index)
large_room_list = list(course_counts[(80 > course_counts) & (course_counts >= 40)].index)
medium_room_list = list(course_counts[(40 > course_counts) & (course_counts >= 15)].index)
small_room_list = list(course_counts[(15 > course_counts) & (course_counts > 4)].index)
# 강의실 이름 붙이기
for i in range(len(auditorium_list)):
df.loc[(df["course name"] == sorted(auditorium_list)[i]) & allowed, "room assignment"] = "Auditorium-" + str(i + 1)
for i in range(len(large_room_list)):
df.loc[(df["course name"] == sorted(large_room_list)[i]) & allowed, "room assignment"] = "Large-" + str(i + 1)
for i in range(len(medium_room_list)):
df.loc[(df["course name"] == sorted(medium_room_list)[i]) & allowed, "room assignment"] = "Medium-" + str(i + 1)
for i in range(len(small_room_list)):
df.loc[(df["course name"] == sorted(small_room_list)[i]) & allowed, "room assignment"] = "Small-" + str(i + 1)
# column 이름 바꾸기
df.rename(columns={"room assignment": "room number"}, inplace = True)
# 테스트 코드
df
-.. 아직도 파이썬이 익숙하지 않은 듯..
- 저 [i]를 할당하는 건 그 다음 행으로 넘어가는 게 아닌가 싶은데,, 지피티는 아니래, 다른 과목명으로 넘어가는 거래...
.....하 진짜.. 다시 들으면서 해봐야 할듯..
'Data Science > Pandas' 카테고리의 다른 글
| [EDA] 가설 검정 전에 data set을 살피는 단계 (3) | 2024.06.03 |
|---|---|
| [Pandas] boolean indexing 불린 인덱싱, 다중 조건 인덱싱 (0) | 2024.05.31 |
| [Pandas] DataFrame 값 수정/추가/삭제, header/index 명 지정하기 (0) | 2024.05.28 |
| [Pandas] DataFrame indexing 문법 정리 (이름, 위치) (1) | 2024.05.27 |
| [Pandas] 인덱싱 indexing, 슬라이싱 slicing, 필터링 filtering (0) | 2024.05.26 |