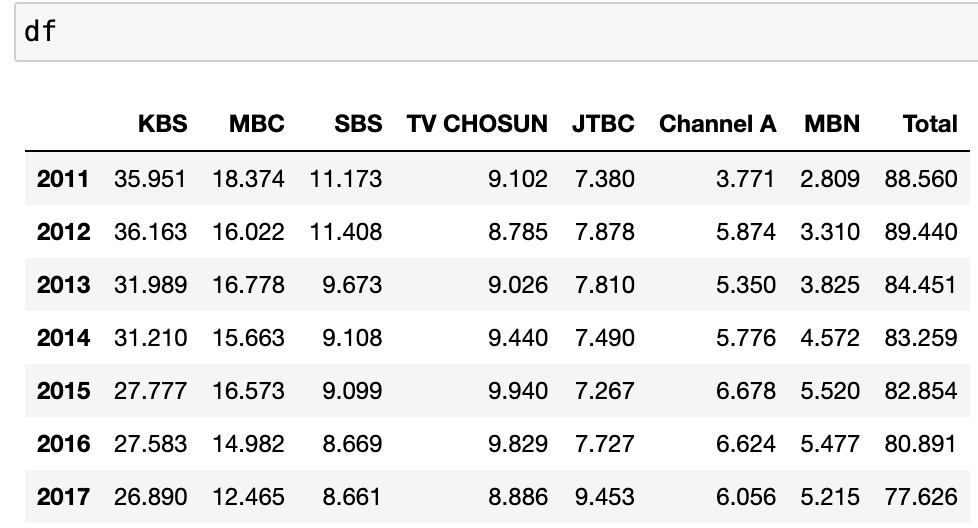
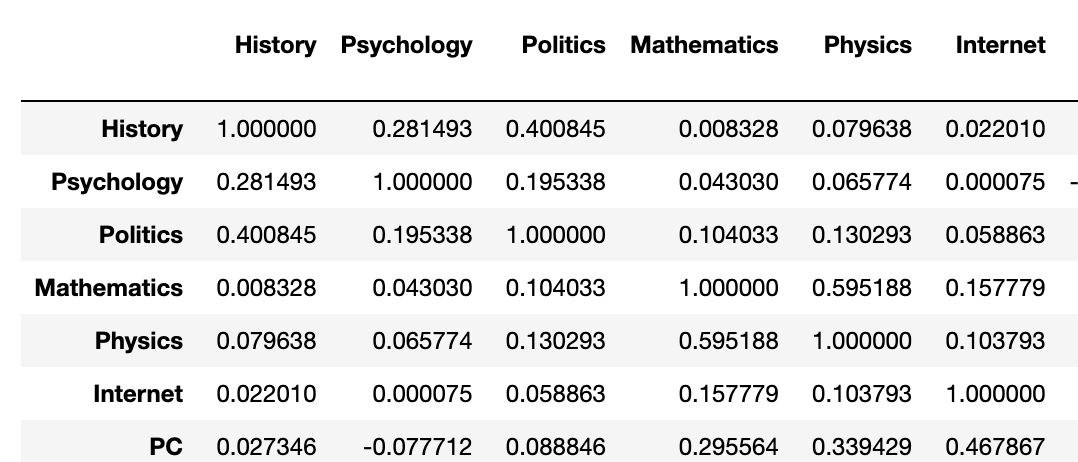
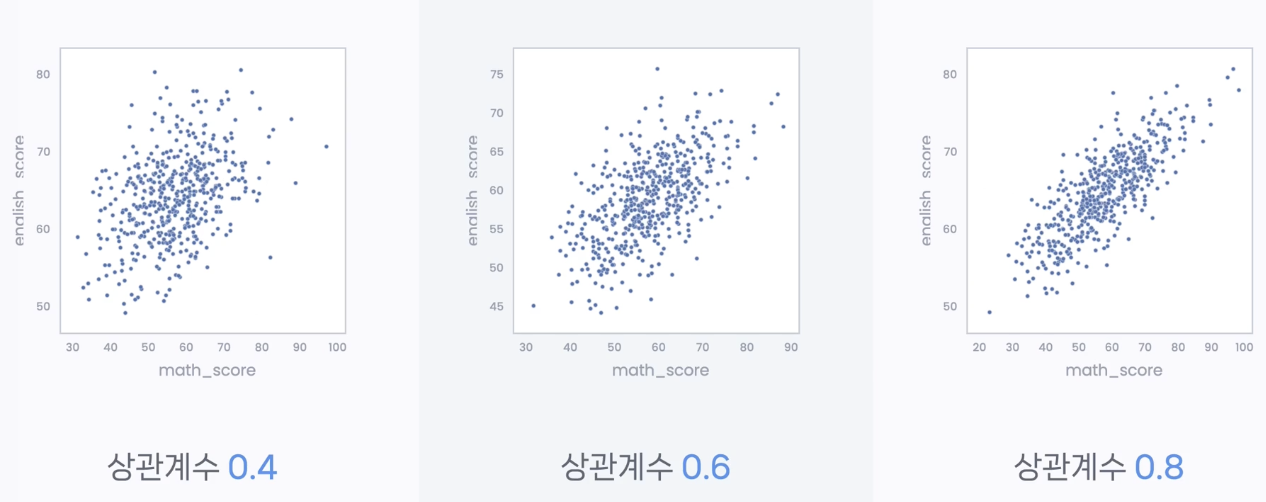
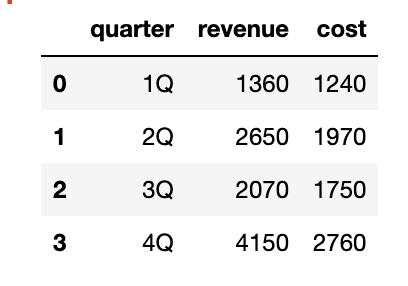
# 코드잇 데이터 사이언스 강의 듣는 중- .sum(axis='colums') - 전처리 단계에서 필요한 변수 생성할 때 유용함. 일일히 행렬 값을 전부 치지 않아도 됨. df.sum(axis='columns')#변수에 넣어주면 계산하기가 더 편해짐df['Total']= df.sum(axis='columns') --> then, 값이 마지막 열로 바로 추가됨. - 직선 그래프는 y='' 만 넣어주면 됨. df.plot(y='Total') --> 명백하게 해가 지날 수록 tv 시청률이 줄어드는 것을 확인 가능 - 지상파/종편 비교 하고 싶으면, 각 값을 생성해주면 됨.df['Group1'] = df.loc[:,'KBS':'SBS'].sum(axis='columns')df['Gro..