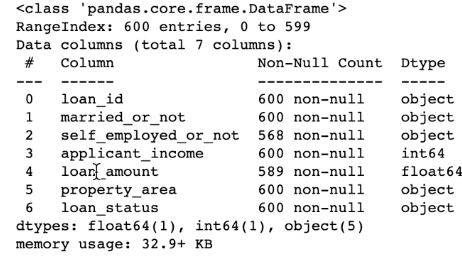
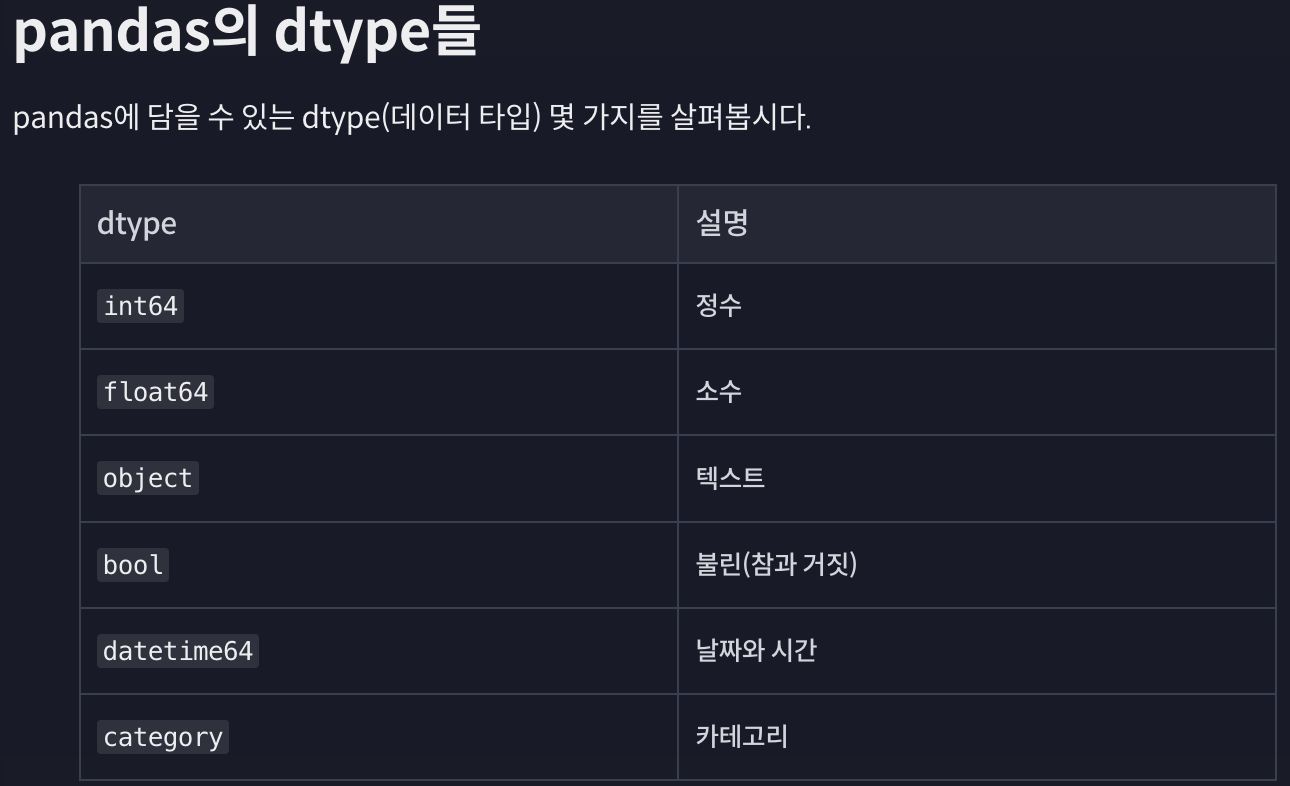
#코드잇 데이터 사이언스 강의 듣는 중#데이터 사이언스 Toolkit renewal 버전 다시 듣는 중 ...ㅎ 진작에 이걸 설명해 주시지..뭐.. 실습하면서 익히긴 했지만, 계속 헷갈렸던 내용이라서.. 정리한다..ㅎ++ 이전 강의보다 훨씬 순서도 깔끔하고 디테일하게 설명해주심. 근데 이전에 했던 내용을 안 다루는 메소드가 많아서 리뉴얼 전이랑 같이 보면 좋을 듯. - .iloc, .loc 은 원래 포스팅에 설명을 추가했기에 제외하고 조건문 넣은 불린 인덱싱.. 이게 길어져서 그런 지 생각보다 헷갈린다. 1. 조건문만 쓰면 --> 불린 값을 시리즈로 출력import pandas as pdburger_df = pd.read_csv("data/burger.csv", index_col = "product..