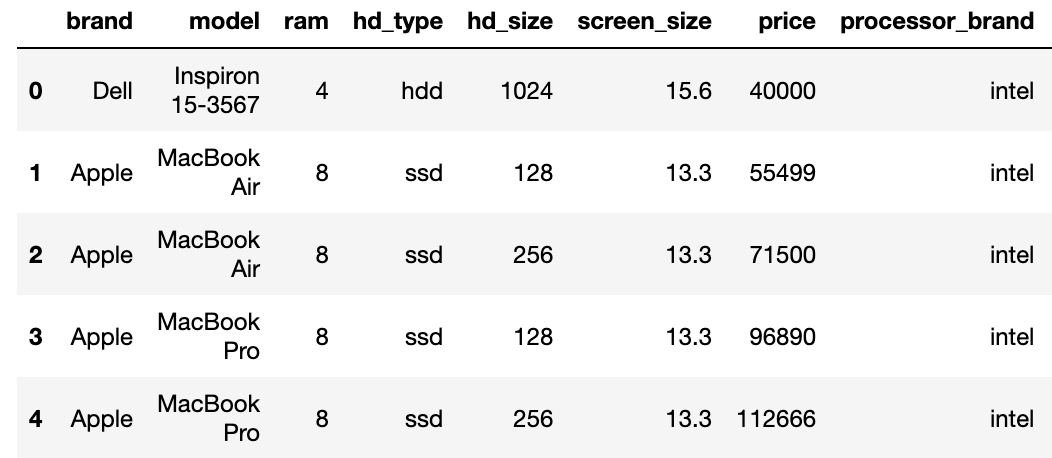
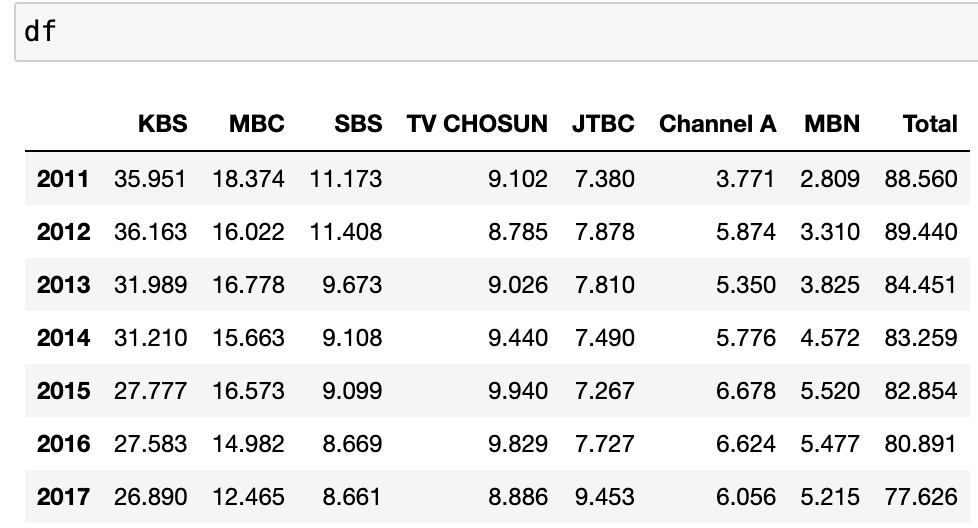
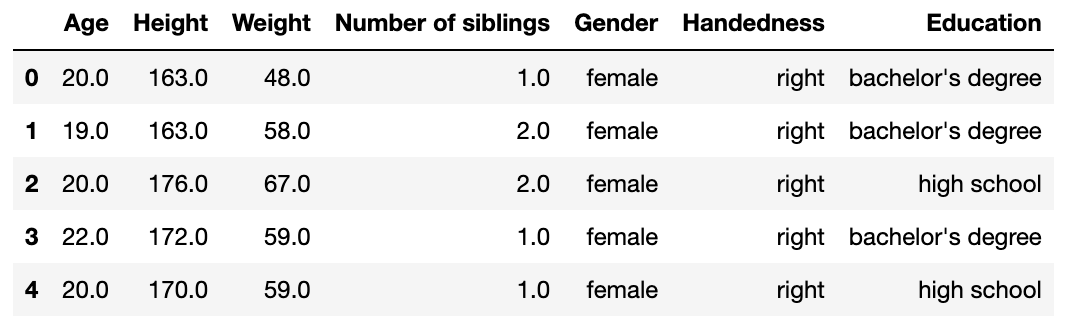
# 코드잇 데이터 사이언티스트 강의 듣는 중 1) .duplicated() airbnb_df.duplicated() #true 중복 값. --> 결측 값 여부에 따라서 true or false // 있으면 True - 이거로는 총 개수 확인이 어렵기 때문에 .sum()을 해줌airbnb_df.duplicated().sum()#2#중복을 인덱싱 한 값에서도 sum 확인 가능. 대신 인덱싱은 풀고 조건만 넣어야 함. #first와 last의 값은 같지만, False의 값은 예외도 추가되서 더 많아짐. airbnb_df.duplicated(subset='id').sum()#6 --> 이건 전체 값이 중복되는 지 여부가 디폴트임. - 인덱싱하면airbnb_df[airbnb_df.duplicated(..