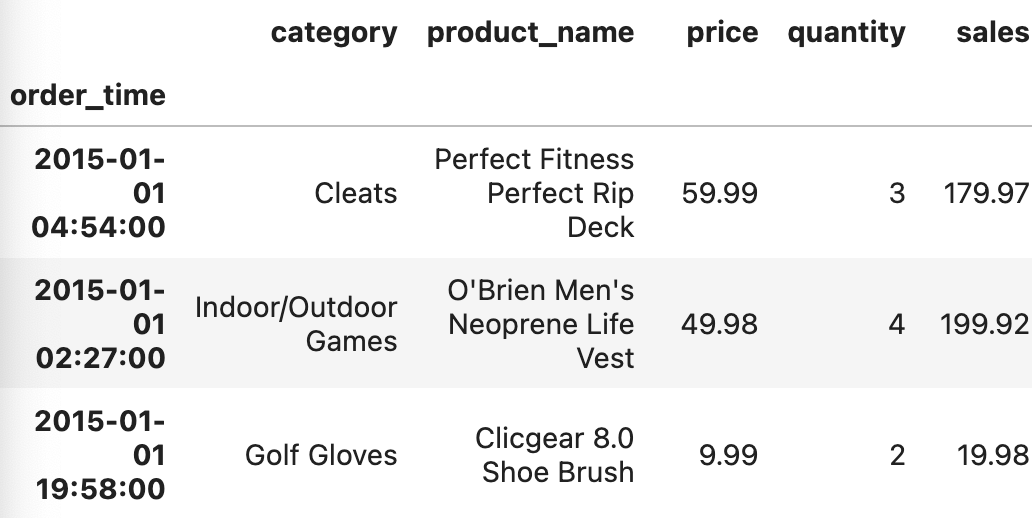
# 코드잇 데이터 사이언티스트 강의 듣는 중- .resample() - 일자 별로 합계나 평균을 계산해서 보고 싶을 때 사용.- datetime이 인덱스로 설정되어 있어야 함. - 일단, 인덱스로 설정하기 order_df = pd.read_csv('data/order.csv', parse_dates=['order_time', 'shipping_time'])order_df = order_df.dropna()#인덱스 설정order_df = order_df.set_index('order_time')order_df --> order_ time이 인덱스가 됨. - .resample()에 인자로 기준값을 넣어주면 됨. - 원하는 시간 간격 기준을 넣으면 됨 --> 'D' ; 하루, 'M' ; 월,..