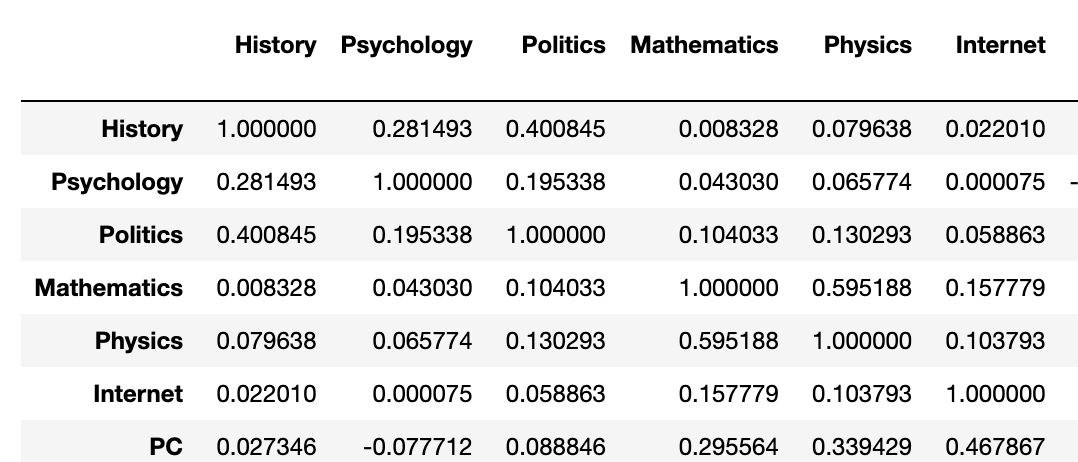
# 코드잇 데이터 사이언스 강의 듣는 중 - 서로 관련이 있는 집단들을 묶어서 분석하는 것- sns.clustermap() - 강의에서는 상관이 있는 것들을 묶는 예제를 보여줬는데, 실제로는, 상관.... 보다는 변수들 간의 관계나 값의 분포 차이에 따라서 군집을 나눔. + 군집분석은 data driven 이기 때문에 일반화 하기가 어렵다는 문제가 있지만, 확진적 요인 분석 CFA 과 잠재 프로파일분석 LPA으로 논문을 썼기 때문에 흥미로운 결과를 많이 뽑아낼 수 있다고 생각하는 편이다. - 필요한 칼럼만 분리하고.interests = df.loc[:, 'History':'Pets']interests.head() - 상관을 아예 변수에 넣음.corr = interests.corr()corr - 역사..