728x90
*elice 강의안

- 수염의 길이로 데이터의 분포도 확인이 가능함.
- 이게 sql할 때 이중 그룹바이였나.. 하여간 좀 복잡하게 하는 방법이 있었는데..
import numpy as np
import pandas as pd
import matplotlib as plt
# 데이터 불러오기
mart = pd.read_csv("mart.csv")
print(mart)
# Q1.지역별로 선호하는 마트
region_crosstab = pd.crosstab(mart["region"], mart["mart"])
print(region_crosstab)
# Q2. 가족구성원의 수별로 선호하는 마트
famnum_crosstab = pd.crosstab(mart["family_num"], mart["mart"])
print(famnum_crosstab)
############### 결과
mart costco emart homeplus lotte
region
chungcheong 3 2 1 1
gangwon 1 3 3 2
gyeongsang 0 1 2 7
gyonggi 0 4 2 3
jeolla 2 2 3 0
seoul 2 2 3 1
mart costco emart homeplus lotte
family_num
1 1 4 5 1
2 2 4 3 5
3 2 1 3 2
4 2 3 3 3
5 1 2 0 3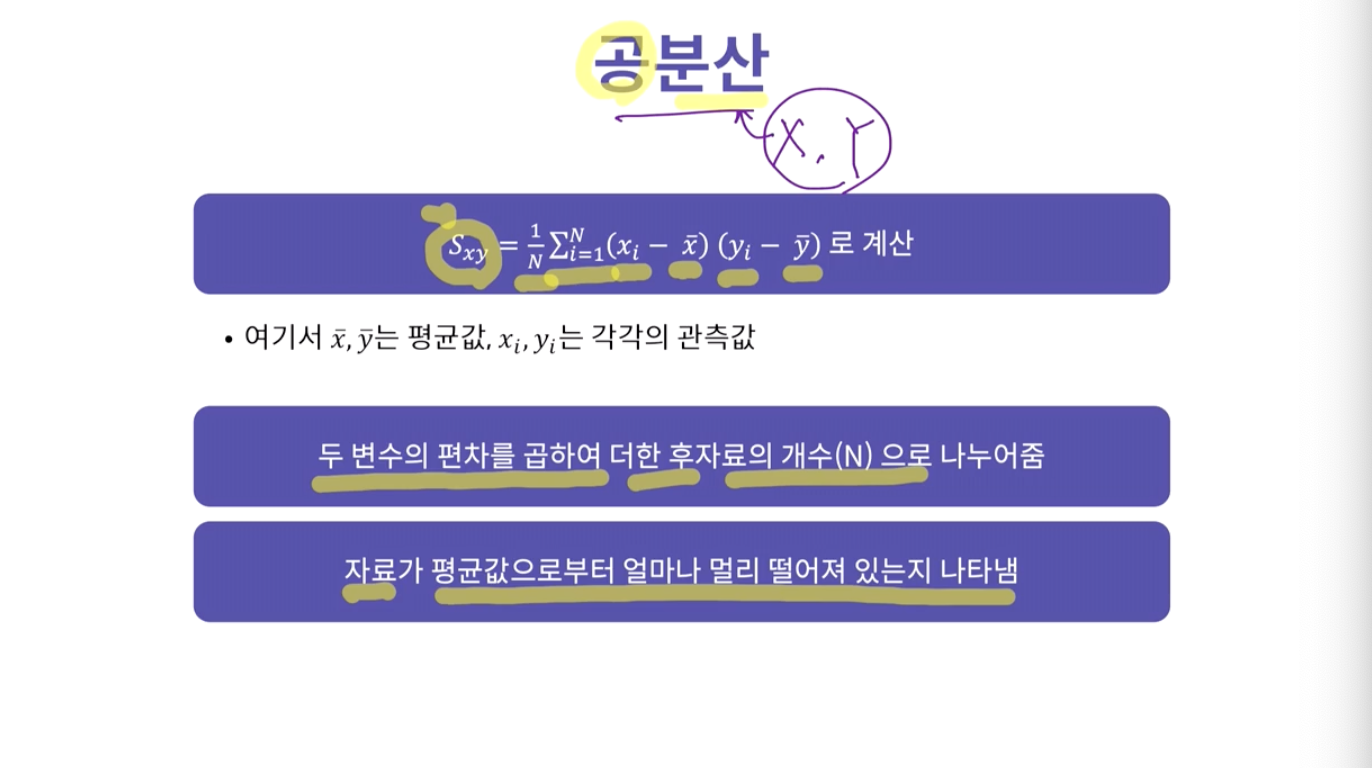



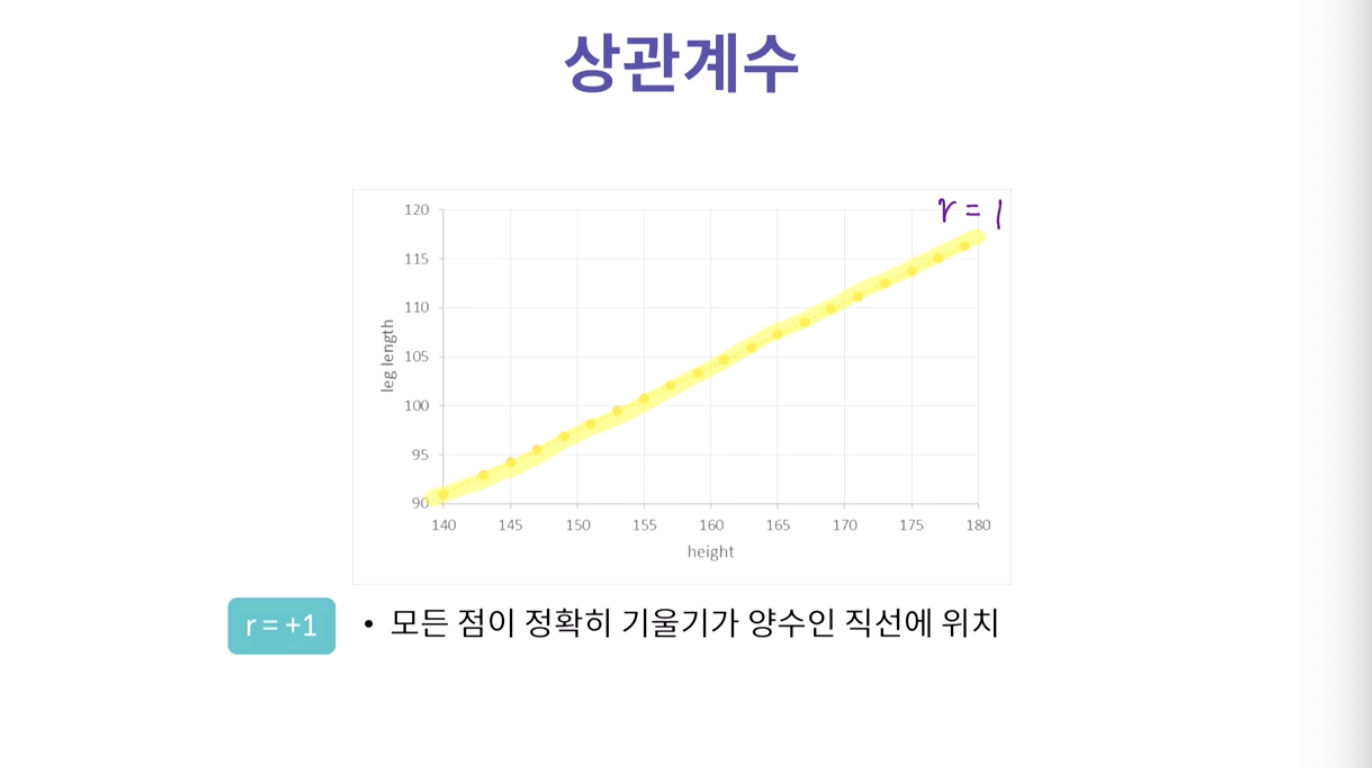
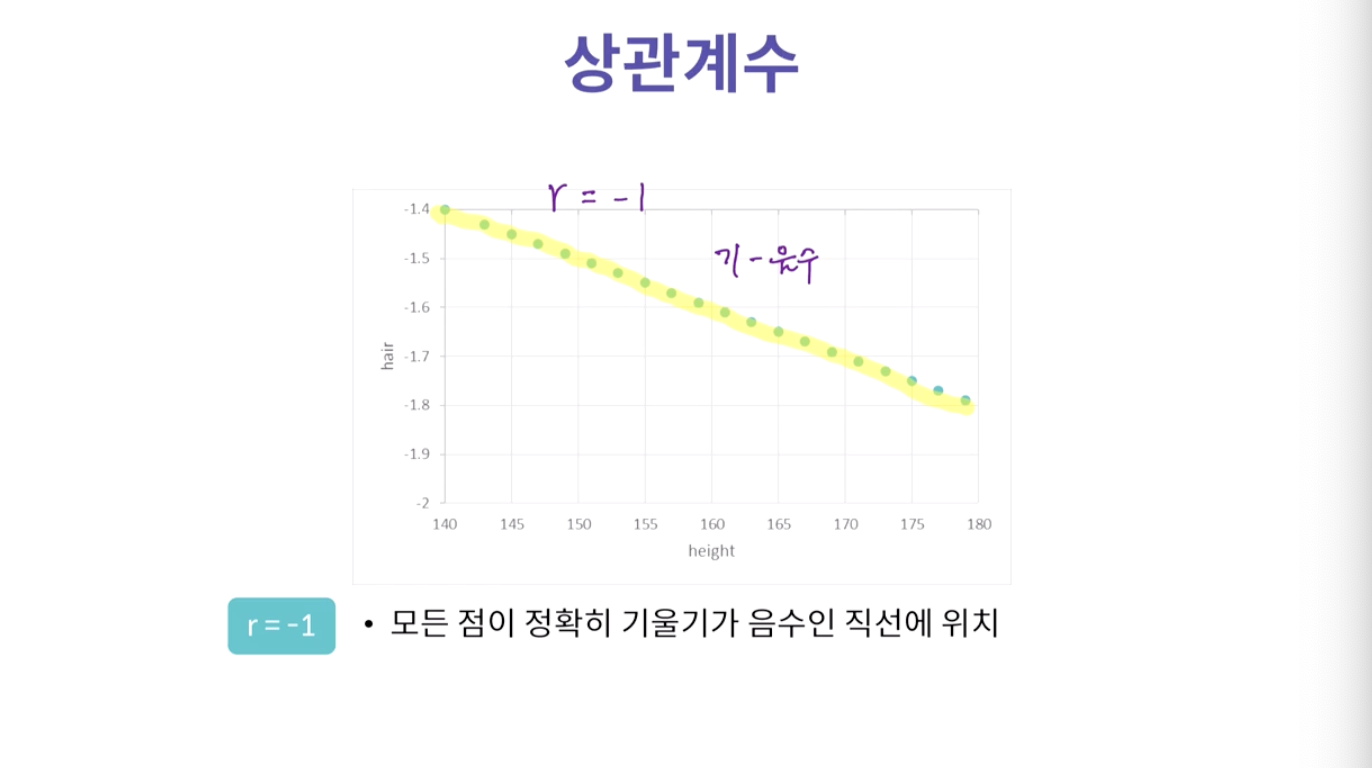
- 기울기가 높다고 상관계수가 높은 게 아니라, 그냥 직선이면 상관계수가 높은 것.
-> 값이 정확히 떨어지는 거니깐

- 직선과 값들의 거리가 멀기 때문에 (오차가 크기 때문에) 상관계수가 0에 가까울 확률이 큼


- 산점도 봤을 때 난리면 상관계수 안 써도 됨.



-> 상관 떴다고 다 뜬게 아님. 제 3변수 영향 확인

728x90
반응형
'Data Science > Statistics' 카테고리의 다른 글
| [elice 통계] 추론 및 가설검정 (이산확률 분포) (1) | 2025.06.12 |
|---|---|
| [elice 통계] 확률(사건/확률, 순열/조합, 조건부확률/독립, 확률분포) (0) | 2025.05.28 |
| [elice 통계] 논리적 자료의 요약(평균, 중간값, 최빈값, 분산, 사분위수, cv, 도수분포표) (1) | 2025.05.23 |
| [elice 통계] 자료의 형태, 범주형/수치형 자료 (0) | 2025.05.21 |
| [기초통계] 누적 값 계산하기, .cumsum(), .cumprod() (3) | 2024.06.12 |