# 코드잇 데이터 사이언스 강의 듣는 중
- seaborn을 쓰면 matplotlib 보다 더 적은 코드로 근사한 그래프를 그릴 수 있음.
- statisctical data visualizaton 통계 기반 데이터 시각화 툴임.
- 간편하게 근사한 그래프를 원하면 seaborn을 쓰고 원하는대로
커스텀해서 그래프를 만들고 싶으면 matplotlib을 쓰면 됨.
- seaborn 라이브러리에서 KDE를 하여 그래프를 매끄럽게 조정할 수 있음.
- 이게 뭐지 했었는데..?
- 심리통계에서도 매일 쓰는 것이 확률밀도 함수였지만, 그 자체보다는 유의확률에 따라 기각 여부에만 집중했었기 때문에 그냥 조정된 KDE그래프만 봐서 모른 것이었음. 그것도 그냥 데이터가 무한대라고 가정하고 그래프를 추출하는 것이다라는 수준으로만 배웠음.
pip install seaborn==0.13.2
import pandas as pd
import seaborn as sns
body_df = pd.read_csv('data/body.csv', index_col=0)
body_df.head()
body_df['Height']
- 빈도를 그래프로 만들어줘야 하니깐, 개수를 각각 세어줌.
body_df['Height'].value_counts()
- dataframe 정렬하려면 .sort_index() 하면 됨.. (진작.. 알려주지.. 괜히 ascending = True 쓰고 있었잖아. )
body_df['Height'].value_counts().sort_index()
- 그리고 plot을 그리면 행이 무한대에 가깝지 않기 때문에 그래프가 튐.
body_df['Height'].value_counts().sort_index().plot()
- then, sns.kdeplot()을 사용하면 PDF의 면적이 1인 그래프로 보정됨.
sns.kdeplot(body_df['Height'])
- 너무 매끄러우면 오히려 값을 왜곡하는 것일 수 있기에 bw =''로 대역폭(bandwidth)을 조절 해줌.
- bw가 작아질수록 원래 값에 가까워짐. so, 어느 정도로 조정할 지를 주의할 것.
sns.kdeplot(body_df['Height'], bw = 0.05)
<히스토그램>
- y를 따로 넣어주지 않음.
- 히스토그램은 그냥 한 가지 값에 대해서 분포를 살피는 것이기 때문에, y 파라미터를 빼줌
- x 대신 y를 넣어줘도 됨.
- 핵심은 파라미터는 1개임.
sns.histplot(data=df, x='registered')
plt.show()
--> 파라미터를 y로 주면 가로로 그려짐.
--> pandas plot은 막대가 10개가 나오지만,
seborn은 데이터에 맞게 알아서 막대 개수가 나타남.
sns.histplot(data=df, x='registered', bins=10, hue='workingday')
plt.show()
--> 원하면 bins 개수를 설정할 수도 있고,
- hue로 이산변수 확인도 가능함.
--> 근데 그냥 이렇게 쓰면 값이 겹쳐져서 나타남.
sns.histplot(data=df, x='registered', bins=10, hue='workingday', multiple='stack')
plt.show()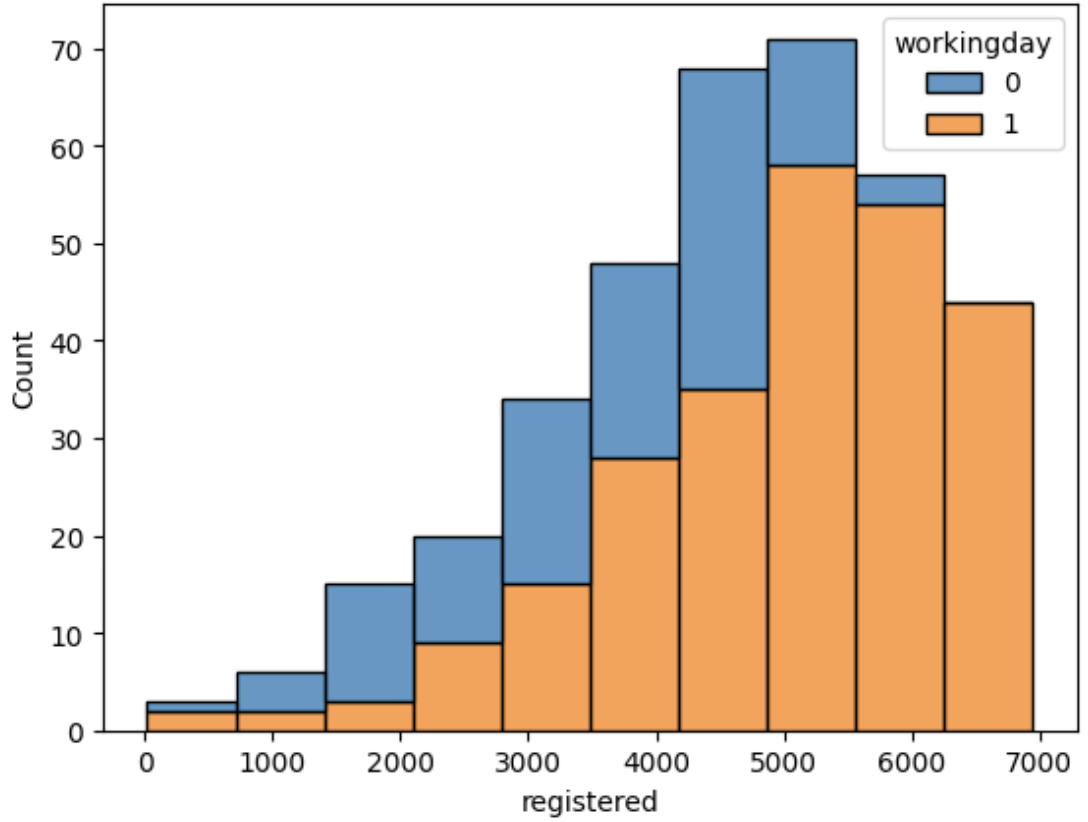
--> multiple='stack' 이걸로 값을 구분해주면, 처음 그래프랑 똑같이 나타나는 데 겹치지 않게 나타나서 보기 편함.
- 위에서는 kdeplot을 그릴 때 파라미터로 df[]를 넣었는데 이번에는 그렇게 안함... 하 또 헷갈리게 하네
sns.kdeplot(data=df, x='registered', bw_method=0.1)
#돌려보면 위나 아래나 똑같음
sns.kdeplot(df['registered'], bw=0.1)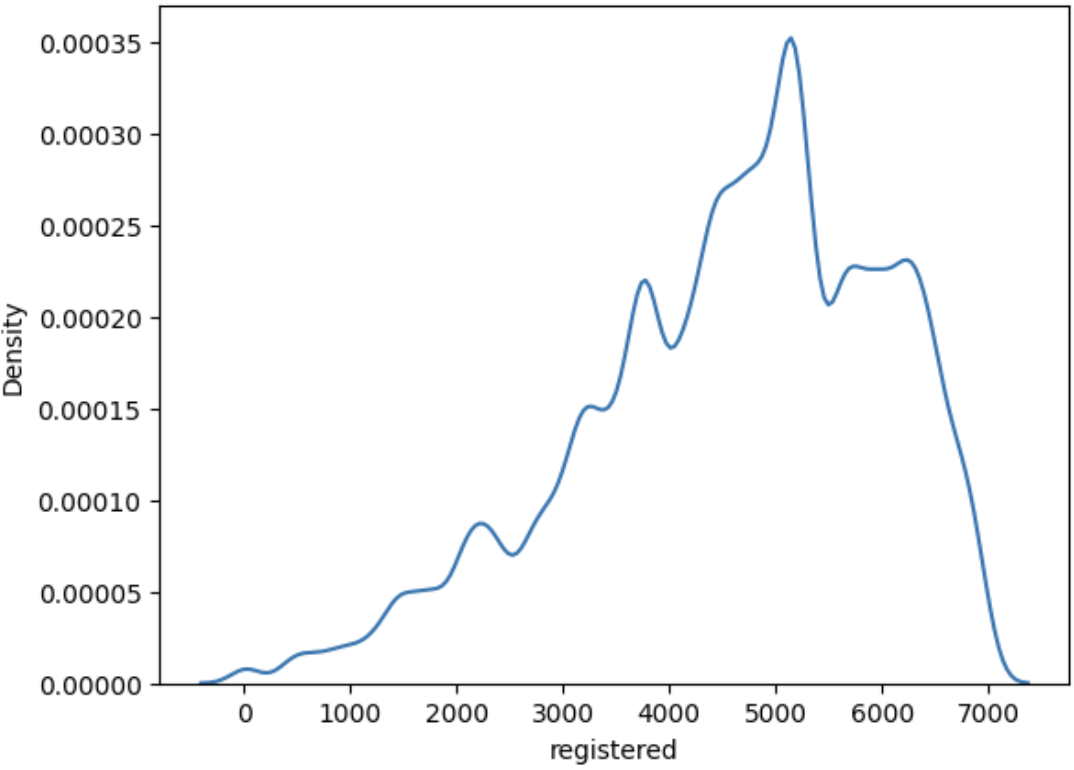
--> bw도 위에선 그냥 했는데 이건 bw_method야.. 왜 통일이 없니..???
sns.distplot(body_df['Height'])
- kde 선도 같이 그려줌.
- sns.distplot()
<violin plot>
- ㅎ 이게 이런 의미인지 이제 알았음 ㅋ.
- kde 를 가로로 양 옆 대칭으로 그려놓은 거임. 한 눈에 그래프 확인 됨.
- 박스 플롯이 가운데에 들어가 있음.
- sns.violinplot(y=)
- 방향을 바꾸고 싶으면 y가 아니라 x에 넣으면 됨.
sns.boxplot(data=df, x='day_of_week', y='registered', palette = 'pastel',
order=['MON', 'TUE', 'WED', 'THU', 'FRI', 'SAT', 'SUN'])
--> order = [] 리스트를 넣어주면 값의 배열 순서를 바꿀 수 있음.
sns.violinplot(data=df, x='day_of_week', y='registered', palette = 'pastel',
order=['MON', 'TUE', 'WED', 'THU', 'FRI', 'SAT', 'SUN'])
--> 박스플롯보다 보기 어렵게 느껴질 수는 있지만, kde 그래프가 추가되서 사실은 정보가가 더 많음.
sns.violinplot(x=df['salary'])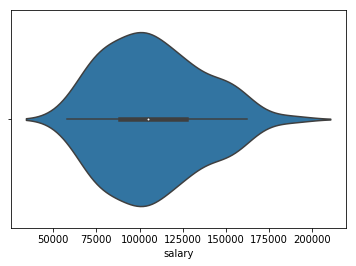
--> x에 넣어주면 kde그래프 방향을 바꿀 수 있음.
<등고선>
- x,y의 kde분포를 3차원으로 보여줌.
- 스캐터보다 분산 정도를 쉽게 확인할 수 있음.
- 강의 에서는 x,y를 따로 부여하지 않고 파라미터에 시리즈를 넣었으나(body_df['Height']),
필요 argument가 1개 인데 2개 부여했다고 에러가 떠서 x,y에 부여함.
- 공식 문서에서는 (data= , x='', y'')라고 되어 있음.
body_df.plot(kind='scatter', x='Height', y='Weight')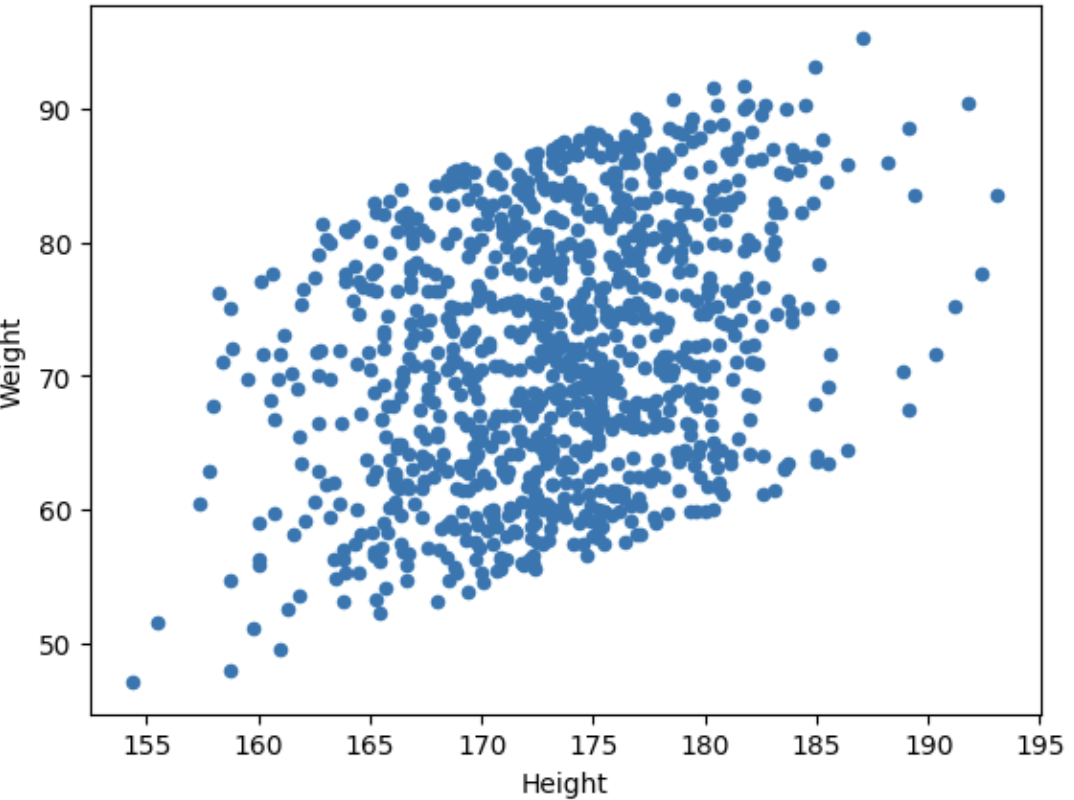
sns.kdeplot(data=body_df, x='Height', y='Weight')
#sns.kdeplot(x=body_df['Height'], y=body_df['Weight'])
- 등고선 간 간격이 가까우면 가파른 상승이고, 완만하면 완만한 곡선임.
- 각각의 분포를 그려놓고 생각해보면 같음.
sns.kdeplot(body_df['Height'])
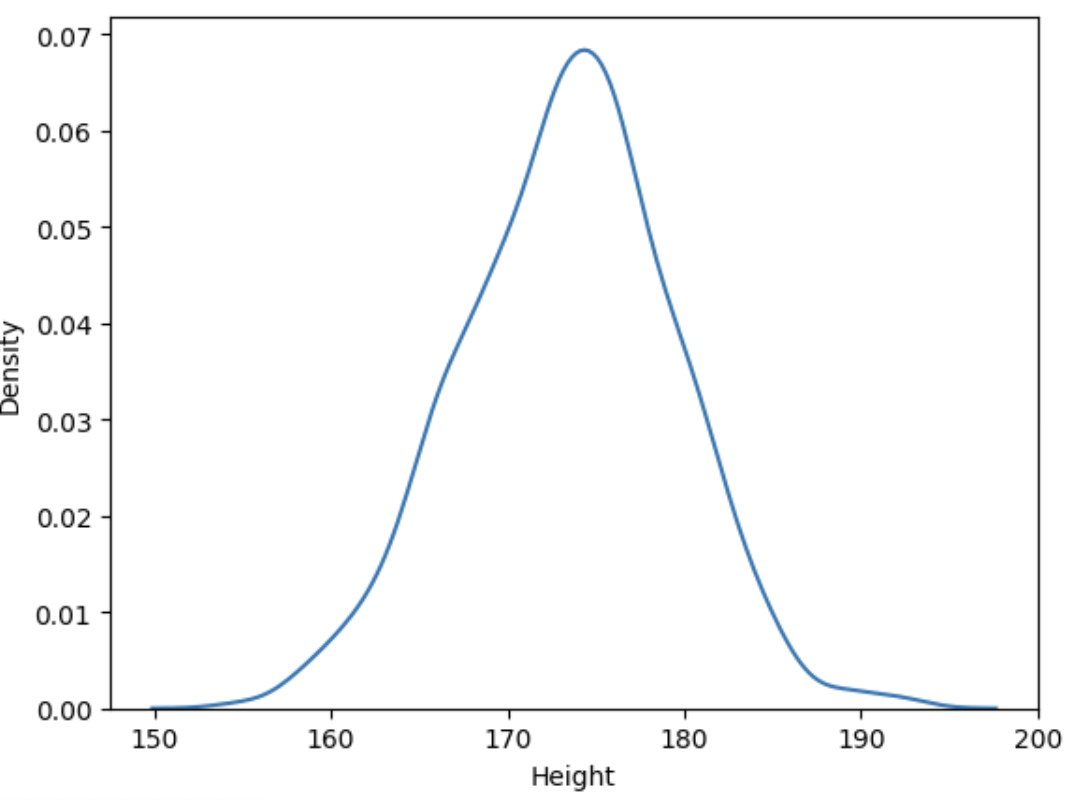
sns.kdeplot(body_df['Weight'])
++ seaborn 공식문서.. 와 재밌는게 너무 많아..
https://seaborn.pydata.org/generated/seaborn.kdeplot.html
seaborn.kdeplot — seaborn 0.13.2 documentation
seaborn.kdeplot seaborn.kdeplot(data=None, *, x=None, y=None, hue=None, weights=None, palette=None, hue_order=None, hue_norm=None, color=None, fill=None, multiple='layer', common_norm=True, common_grid=False, cumulative=False, bw_method='scott', bw_adjust=
seaborn.pydata.org
<lm plot>
- linear model 회귀선을 scatter plot에 그려줌.
- 재밌는 게 회귀선에 shade를 줘서 오차범위까지 나타내는 듯.
sns.lmplot(data=body_df, x='Height', y='Weight')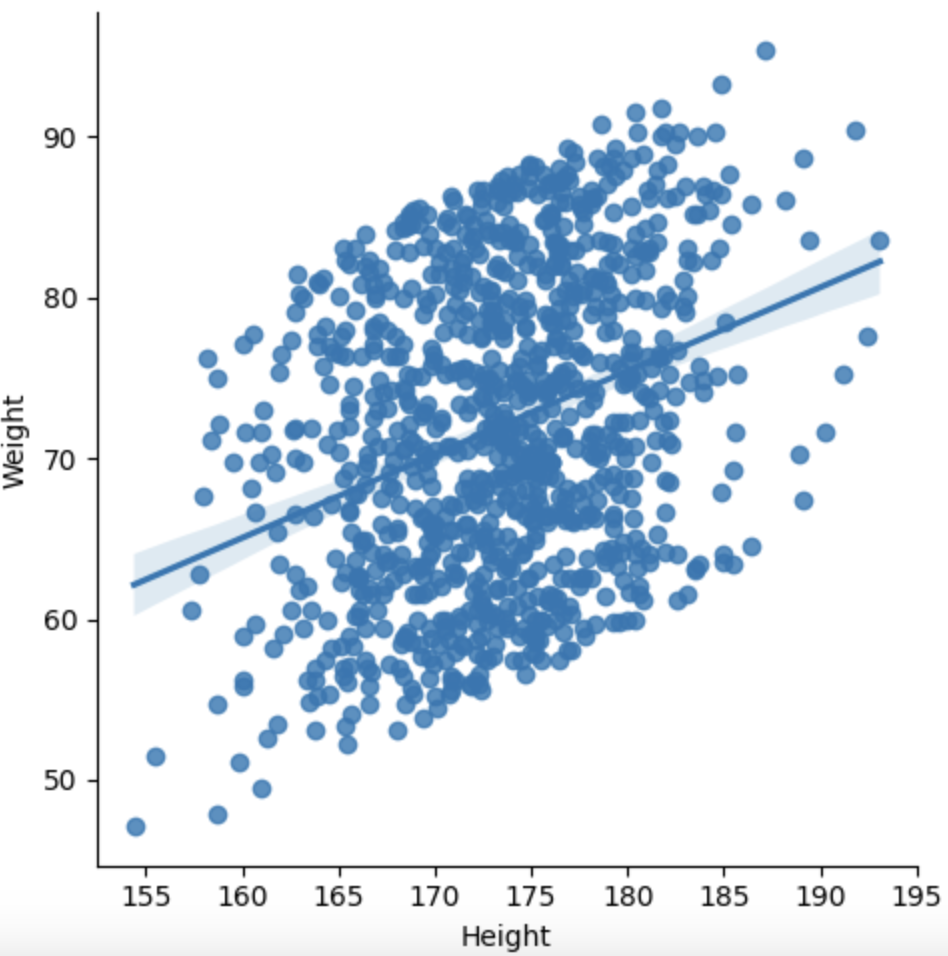
<cat plot>
- categry 별로 확인하고 싶을 때 사용.
- sns.catplot(data= , x='', y='', kind='')
- kind를 안 쓰면 기본형이 strip임
- 여러 종류의 그래프들 다 가능. --> box, violin, strip, swarm etc.
- hue: 색조로 칼럼에 따른 dot을 확인하고 싶을 때, 변수 명을 넣어주면, 값의 개수에 따라서 색칠 됨.
- category 별로 보려면 우선 .unique()를 통해서 몇 개나 나올 지 확인하는 게 좋음.
laptops_df['os'].unique()
#array(['linux', 'mac', 'windows'], dtype=object)sns.catplot(data=laptops_df, x='os',y='price', kind ='box')
sns.catplot(data=laptops_df, x='os',y='price', kind ='violin')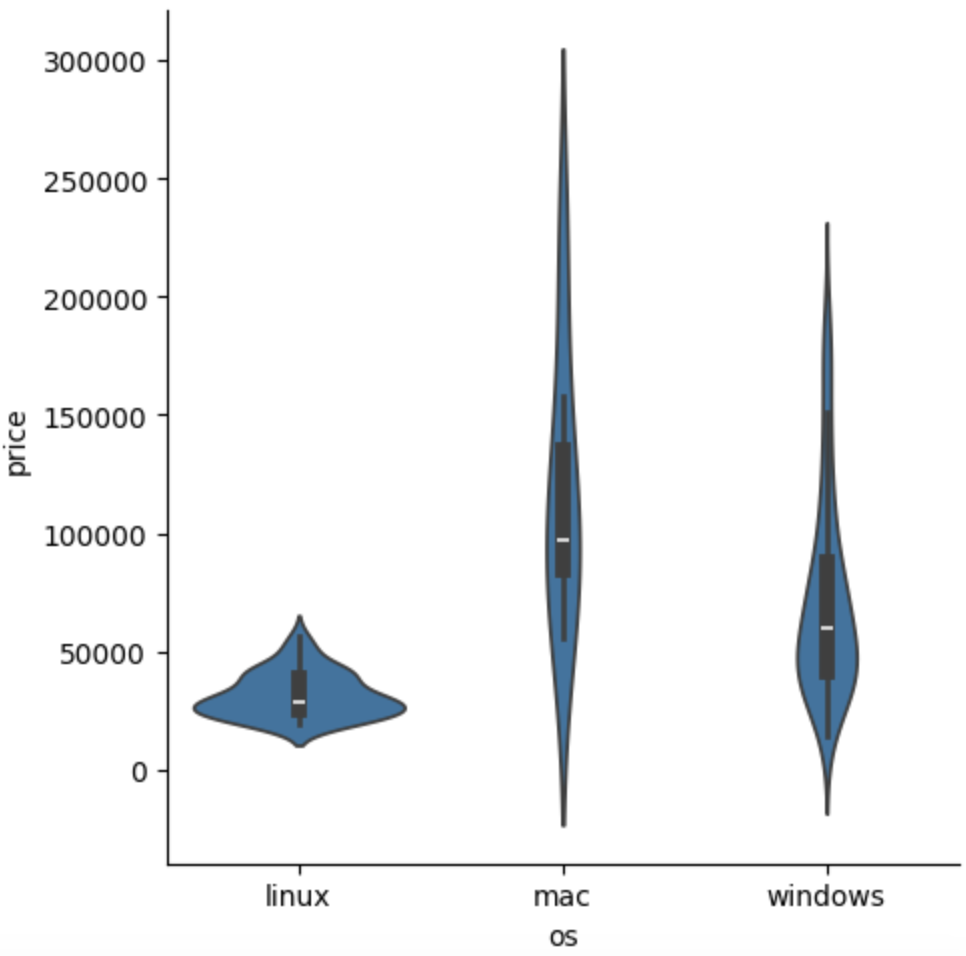
sns.catplot(data=laptops_df, x='os',y='price', kind ='strip')

--> 위 두 plot으로는 제대로 확인이 안됨. 각 카테고리 별로 n수가 몇 개인지 모르기 때문 so, strip 사용하면 대략 알 수 있음.
sns.catplot(data=laptops_df, x='os',y='price', kind ='strip', hue='processor_brand')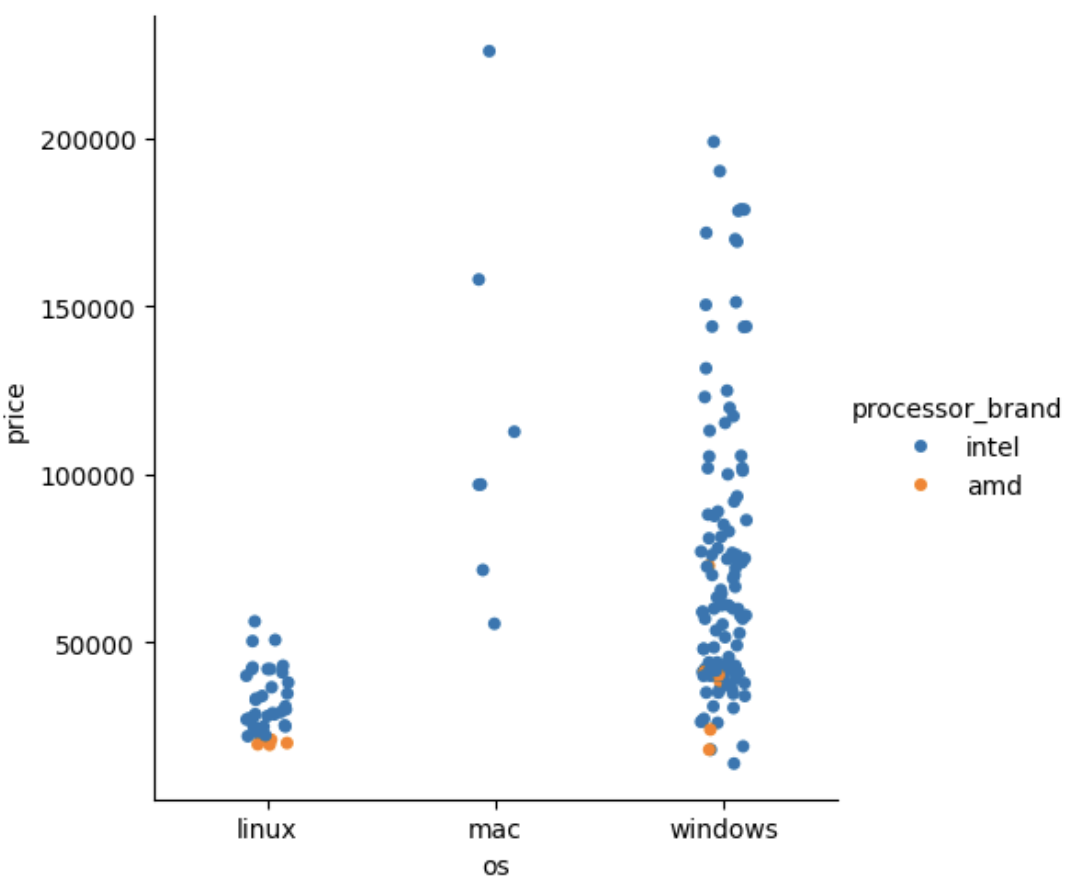
--> 다른 변수의 값에 따른 값을 확인 하고 싶을 땐 hue=''
sns.catplot(data=laptops_df, x='os',y='price', kind ='swarm', hue='processor_brand')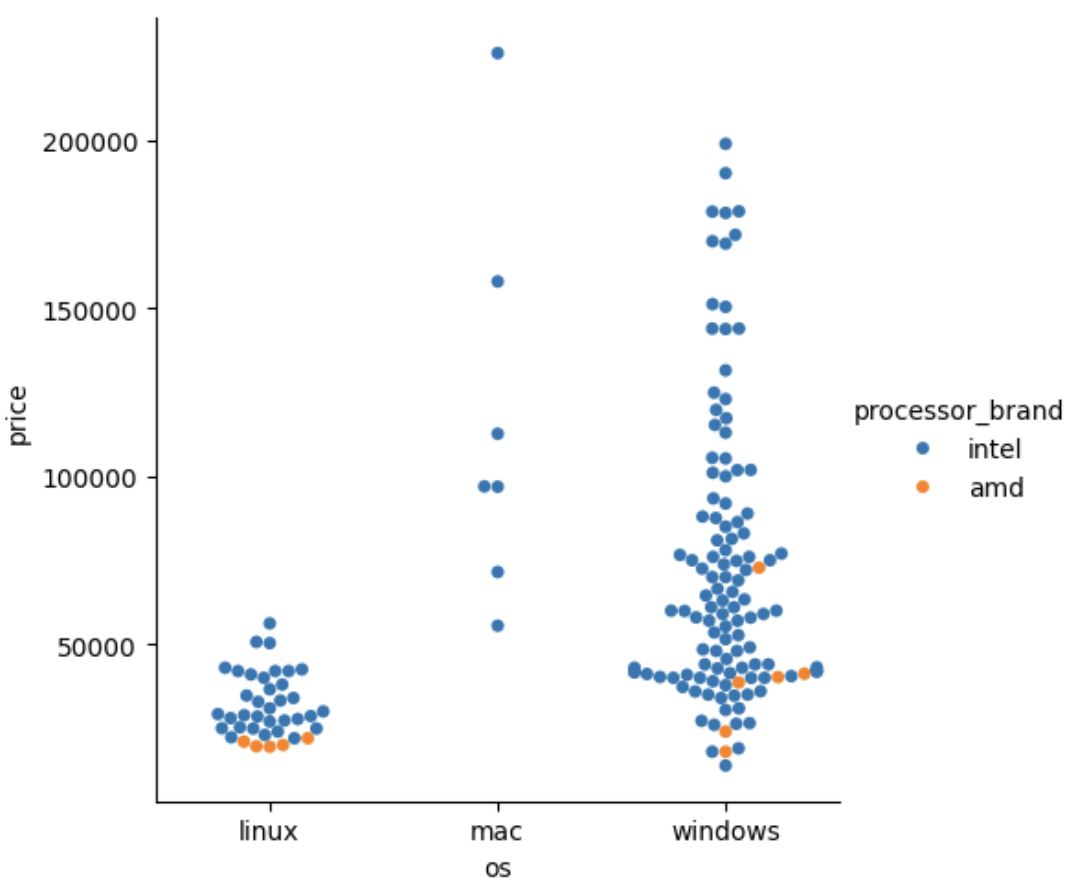
--> 밀집된 곳의 분포가 궁금하면 swarm
+ catplot으로 보려고 합쳐놨지만 기본적으로 strip과 swarm plot도 각자 확인 가능함.
=> 둘 다 많은 양의 데이터 보다는 몇 십개에서 몇 백개 수준일 때 적당함..
스캐터도 그림이 가능해야 하니깐.
- strip plot: 축이 1개인 scatter plot으로 직선으로 dot이 나열됨.
sns.stripplot(data=df, x='month', y='total', hue='workingday')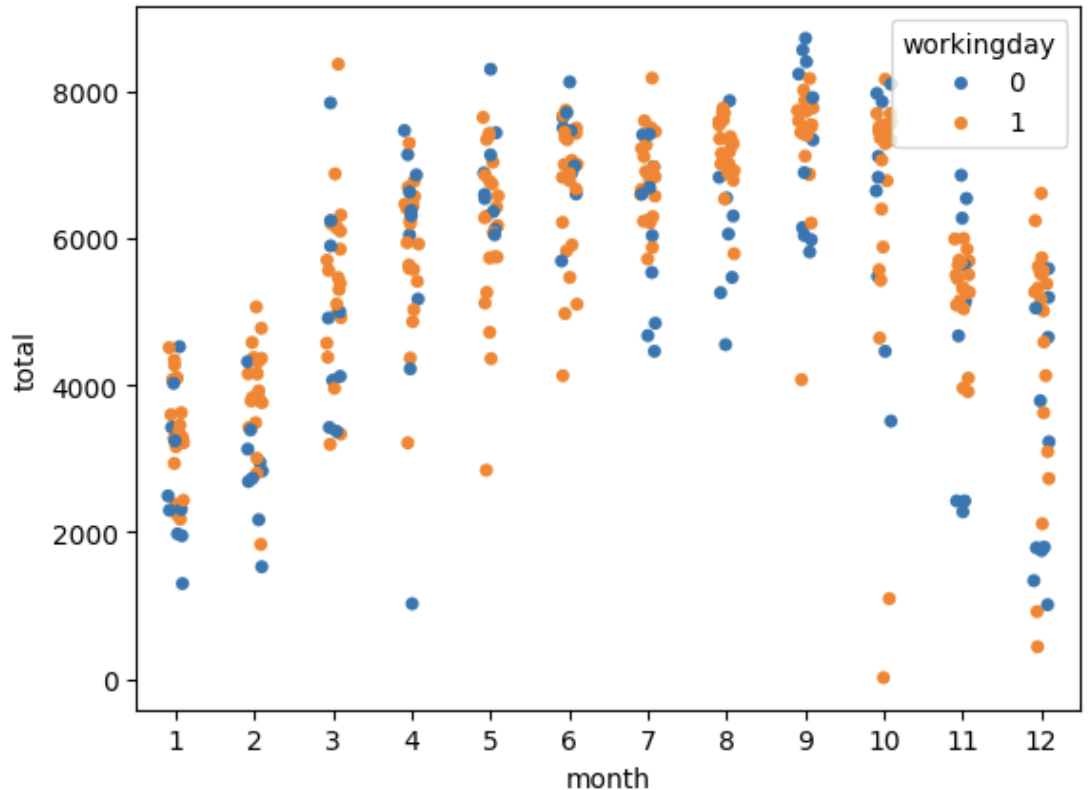
--> 분산 정도가 확인이 되긴 하지만, 굳이 이걸로 봐야 하나 싶긴함.
--> 익숙하지 않아서 그런가 눈에 잘 안 들어옴.
- swarm plot: 겹쳐진 dot을 보기 편하게 해당 위치에 가로로 넓게 펼쳐줌.
sns.swarmplot(data=df, x='month', y='total', hue='workingday')
--> 이러면 뭉친 곳을 확인할 수 있긴 함.
--> 물론 어떤 달에 이용을 많이 하는지 아닌지 알 수 있지만,
굳이 이렇게 까지 확인할 필요가 있나 싶달까..
'Data Science > Visualization' 카테고리의 다른 글
| [Seaborn] 스타일 설정하기, 폰트 설정하기, 그래프 크기 조절하기 (2) | 2024.06.12 |
|---|---|
| [Seaborn] Macbook Air의 jupyter notebook에서 seaborn import 에러 (0) | 2024.06.01 |
| [matplotlib] graph 제목 붙이기, 사이즈 조절, 한글 제목 넣기 (0) | 2024.05.31 |
| [matplotlib] linear graph, bar graph, scatter plot (0) | 2024.05.30 |