# 코드잇 데이터 사이언스 강의 듣는 중
<카테고리 분류>
- .groupby --> 카테고리 분류를 편하게 하는 기능
- DataFrameGroupBy type을 사용하면 분류하는 것이 굉장히 쉬워짐.
+ sql문이 이건가..?
- 하여튼 변수에 groupby 메소드를 쓰면 알아서 보기 편하게 변수에 따른 통계치나 플랏을 볼 수 있게 만들어줌.
- 새로운 변수를 따로 만들어서 사용하는 것이 편리한 듯 --> type은 DataFrameGroupBy
nation_groups = df.groupby('brand_nation')
type(nation_groups)
#pandas.core.groupby.generic.DataFrameGroupBy
- 그럼 이것저것 메소드 가능해짐
- .count() --> 각 변수 별로 카운트 해줌
nation_groups.count()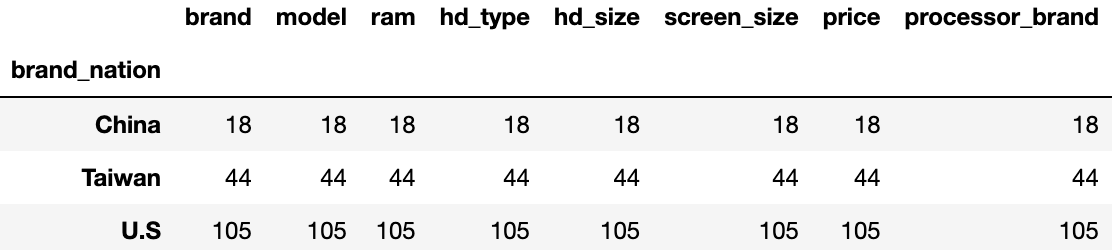
- .first() --> 각 변수 별로 처음 값이 나타남
nation_groups.first()
- .last() --> 각 변수 별로 마지막 값이 나타남.
nation_groups.last()
++ pandas 에러로 .mean(), .max() 는 x
++ 현재 판다스 버젼 '2.2.1'인데도 에러 남..ㅎ
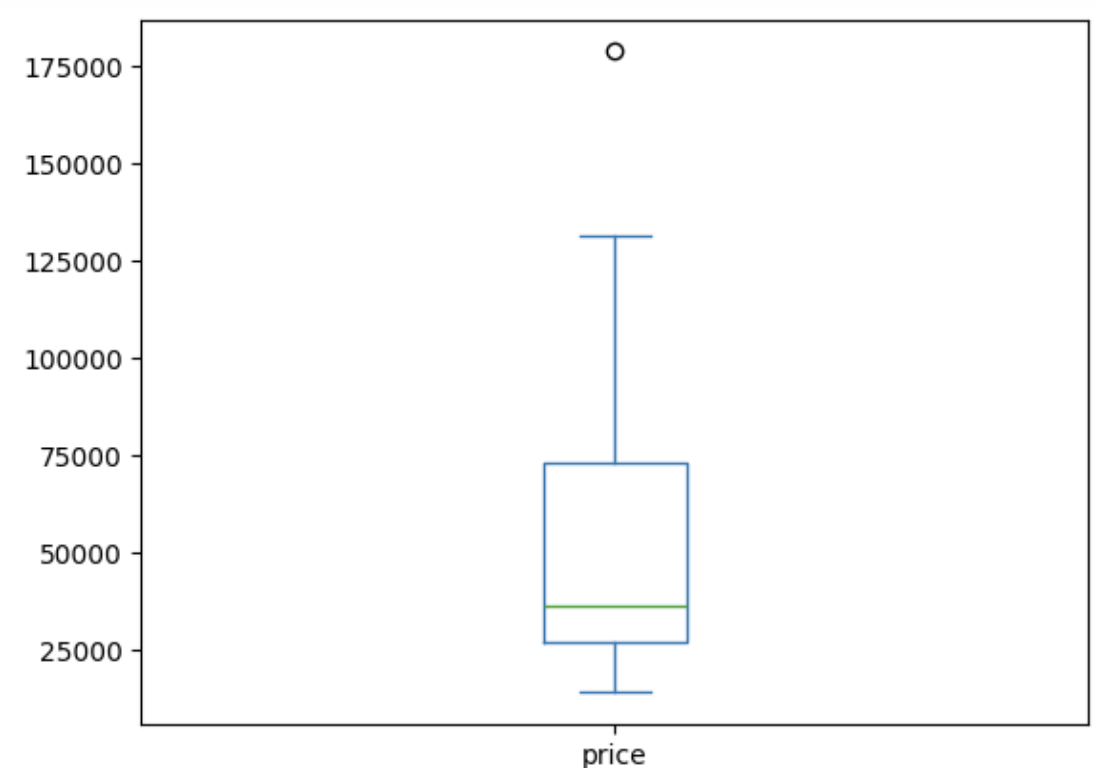
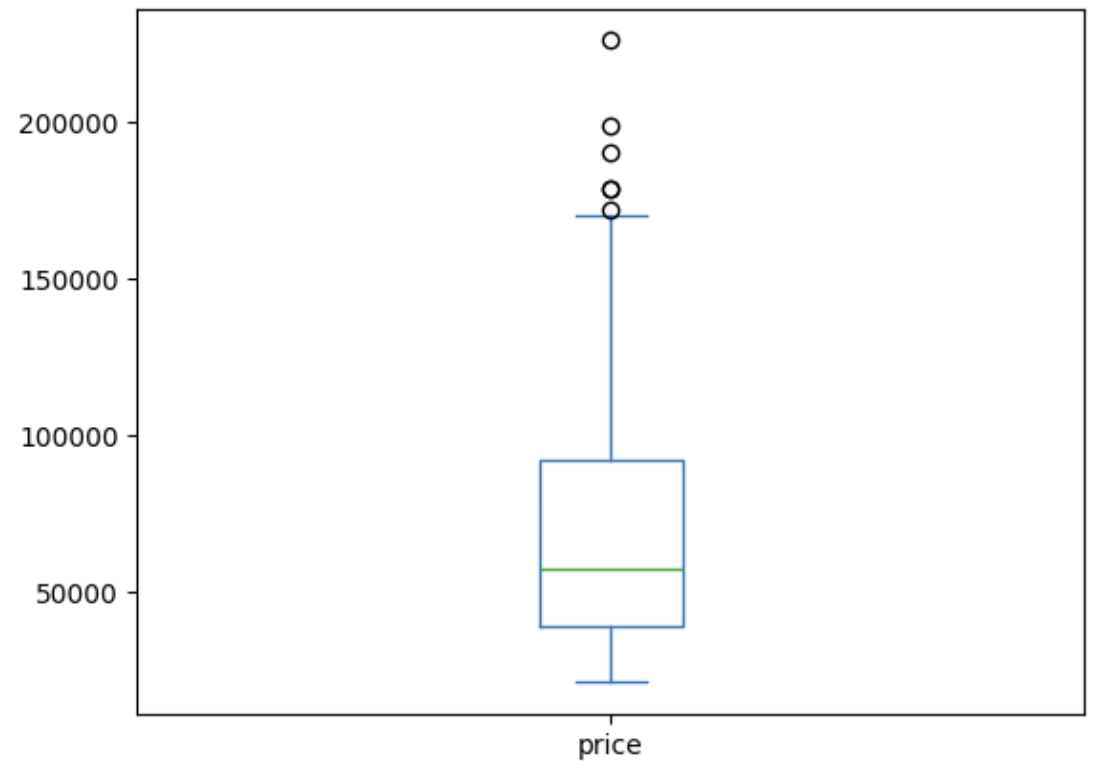
- plot도 가능함.
nation_groups.plot(kind='box', y='price')
--> 순서대로 알아서 그려줌
- histogram도 가능함
nation_groups.plot(kind='hist', y='price')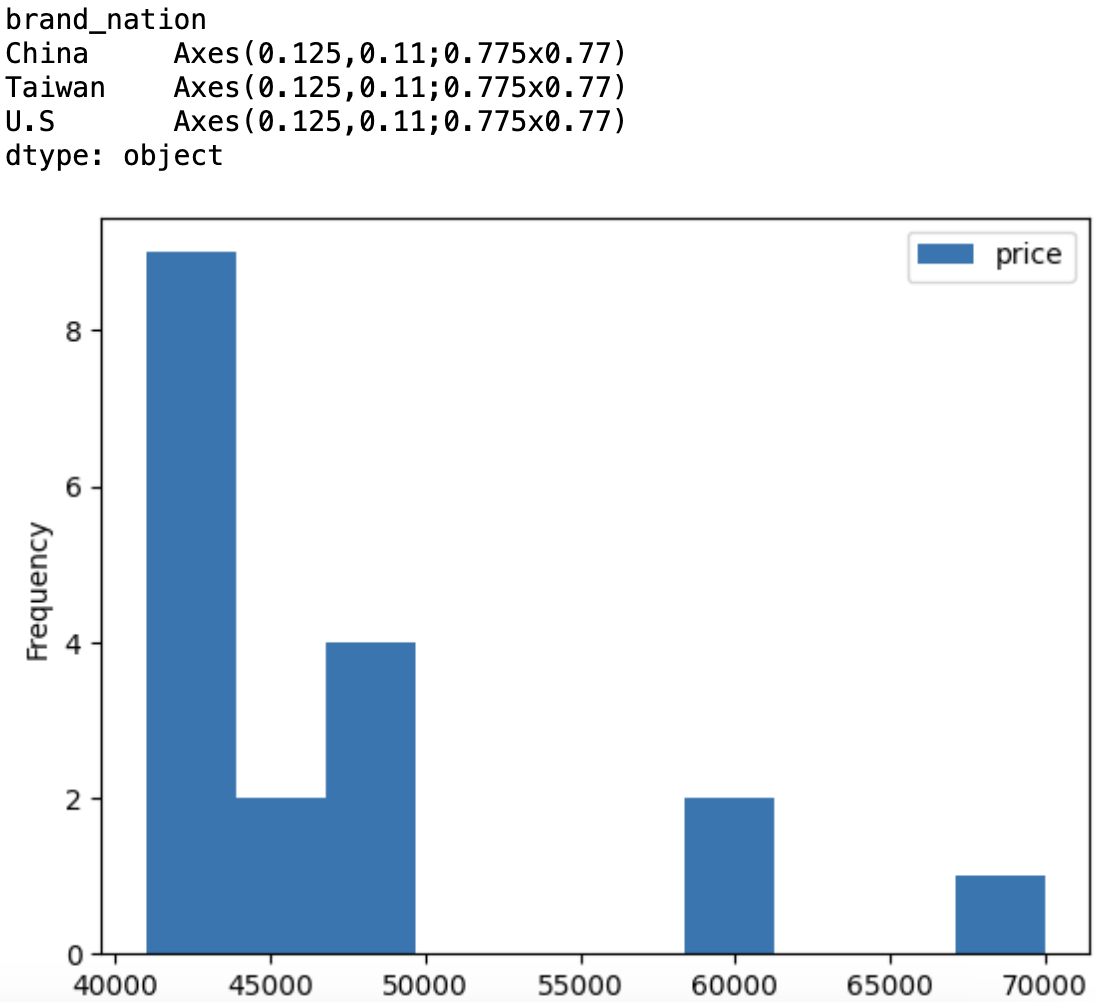
--> 마찬가지로 순서대로 그려줌
<예제1>
- 직업별로 평균 나이확인하기.
- 내 ver1
import pandas as pd
df = pd.read_csv('data/occupations.csv')
occupation_group_mean = df.groupby('occupation')['age'].mean()
occupation_group_mean.sort_values()
- 처음에는 그룹을 나누고, 카운트를 쓰려고 했다가 에러가 떠서, 평균 값을 변수로 빼려고 하는데
잘 되지 않았다.
- 지피티에게 물어보니깐, ['age'] 이런 식으로 인덱스에 변수를 넣어서 직업 군에서 나이의 평균 값을 구했다.
- 해설 ver2
import pandas as pd
df = pd.read_csv('data/occupations.csv')
#직업별로 나누고
occupation_group = df.groupby('occupation')
occupation_group
# 평균을 구한 후
occupation_group.mean()
#그냥 그 값에 sort_values를 하고 by에 age를 넣었음.
occupation_group.mean().sort_values(by='age')
+ ..? by를 안 넣으면, series로 나오고, 아래 해설 버전은 PandasFrame으로 나타남.
- 이유를 잘 모르겠음..?
<예제2>
- 직업별로 여성 비율을 비율이 높은 순서대로 확인하기.
- F와 M을 세야 하는 건가??를 고민하다가 그럼 어떻게 세는 거지?
카운트는 그냥 총합이 나오는 데 변수를 따로 빼서 만들어야 하는 건가??
이러다가.. 머리가 꽝꽝이었다..
- 안 되겠어서 힌트를 봤는데, 숫자를 부여하래서...... 얼마를 부여하라는 거지??? 또 의문만 남다가.
- 지피티와의 대화를 시작했음.
ㅎ..ㅎ F는 1 M은 0으로 바꾸면 된대서 바꿨음.
- 혹시나 값을 바꿔서 2,1로 해보니깐 남자의 수만큼 더해져서 계산하기 편하게 0으로 한다고 생각하면 될 것 같음.
- 평균을 구하는 거니깐, 크기가 커져봤자 그냥 sd의 변화임.
ver1
import pandas as pd
df = pd.read_csv('data/occupations.csv')
df['gender'] = df['gender'].map({'M' : 0, 'F': 1})
occupation_group = df.groupby('occupation')
occupation_group['gender'].mean()
occupation_group['gender'].mean().sort_values(ascending=False)
- 앞선 해설처럼 최대한 변수를 만들지 않고 해보려고 했음.
- ()안에 사전을 바로 넣어도 된다는 게 조금 신기했음. 생각해보면 변수 값이 의미하는 것과 같으니깐 당연히 되는 건데.
해설 ver2
import pandas as pd
df = pd.read_csv('data/occupations.csv')
occupation_group = df.groupby('occupation')
df.loc[df['gender'] == 'M', 'gender'] = 0
df.loc[df['gender'] == 'F', 'gender'] = 1
occupation_group.mean()['gender'].sort_values(ascending=False)
- 해설은 인덱싱으로 각 값을 바꿔줬음.
- 특정 값만 가지고 오고자 ['벡터']를 메쏘드 뒤에 넣어줬음.
+ occupation_group['gender'].mean()과 occupation_group.mean()['gender'] 의 차이?
- 지피티는 자꾸 전자로 코드를 짜고 해설은 그렇지 않아서 차이가 뭔데 결과 값이 같게 나오는지 궁금해서 물어봤다.
- 그냥 순서에 차이인데, ['gender']에서 평균을 구할 것인지, 평균 값들에서 ['gender']를 구할 것인지이다.
- 후자가 괄호 뒤에서 인덱싱을 하니깐 뭔가.. 적절한 위치가 아닐 것 같다는 느낌이 든달까 ㅎ.
'Data Science > Pandas' 카테고리의 다른 글
| [Pandas] 엑셀xlsx 파일 불러오기 (0) | 2024.06.13 |
|---|---|
| [EDA] 데이터 합치기 .merge; inner join, left outer join, right outer join, full outer join (0) | 2024.06.09 |
| [EDA] 카테고리 분류, .map() (3) | 2024.06.07 |
| [EDA] 값 추가, 문자열 필터링 .str.contains(''), 값 분리, .str.split() (0) | 2024.06.07 |
| [EDA] 적용 예제 (0) | 2024.06.07 |