# 코드잇 데이터 사이언스 강의 듣는 중
<엑셀 파일 불러오기>
- . read_excell--> csv랑 동일 함.
loan_df = pd.read_excel('data/loan.xlsx')
- but, 파라미터를 추가해주지 않으면 원하는 모양으로 불러오지 못할 수도 있음.
- 위 코드는 기본적으로 첫번째 시트를 불러옴. 따라서 첫 시트에 아무것도 없으면 .. 안 나옴.
- 원하는 시트를 불러오려면 sheet_name = 을 추가 해줌
loan_df = pd.read_excel('data/loan.xlsx', sheet_name=1)
- 인덱스랑 같은 개념이기 때문에 1을 부르면 2번째 시트를 불러 오는 것임.
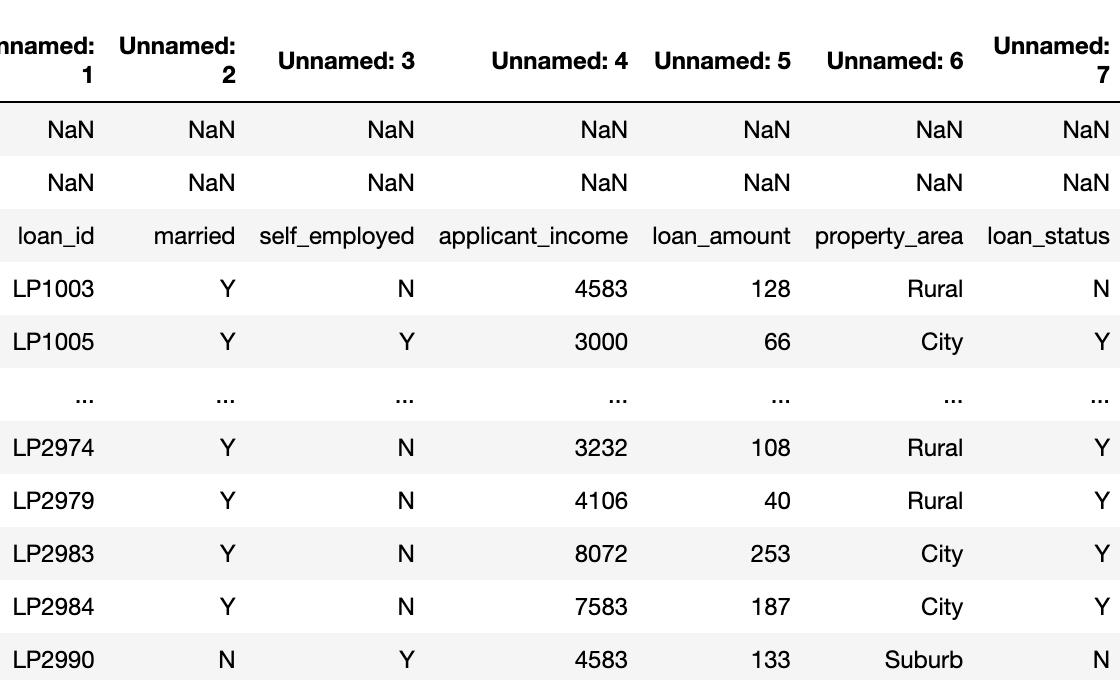
--> 엑셀은 대체로 위에 몇 줄을 비워 놓는데, 판다스는 A1부터 읽음..
--> 그래서 다 Nan이 되어 버림.
--> so, header를 지정해서 그 값부터 불러오게 하는 것이 좋음.
- header= 로 지정하고, usecols =':'로 데이터 열 지정해서 불러오기
loan_df = pd.read_excel('data/loan.xlsx', sheet_name=1, header=3, usecols='B:H')
--> 이렇게 하면 결측치도 사라지고 원하는 대로 데이터를 불러올 수 있음.
--> 기본적으로 엑셀 데이터가 어떻게 구성되어 있는 지가 확인이 되어야 가능함.
++ 더 다양한 파라미터를 확인하려면 문서를 참고하면 됨.
https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html
pandas.read_excel — pandas 2.2.2 documentation
Additional strings to recognize as NA/NaN. If dict passed, specific per-column NA values. By default the following values are interpreted as NaN: ‘’, ‘#N/A’, ‘#N/A N/A’, ‘#NA’, ‘-1.#IND’, ‘-1.#QNAN’, ‘-NaN’, ‘-nan’, ‘1.#IN
pandas.pydata.org
++ 강의를 들을 때마다,
대학원에서 연구할 때 이걸 알았으면 얼마나 좋았을까 생각한다.
기본적인 파이썬을 다루지 못할 때 r로 통계 결과를 확인했었는데,
엑셀 파일로 결과 값을 추출하는 코드를 한참 찾아도 안 나와서 matlab 강의 들을 때 썼던 방법을 응용해서 썼던 기억이 있다.
아예.. 코알못이었는데, 지도교수는 물어도 알아서 찾으라고 하고..... 그래서 그냥 코드를 짰었다.
사실상 처음으로 짠 코드였달까. ㅎ....
그랬었기에 지금 .. 데싸로 길을 틀었지만.. 참.... 가끔 아니 자주 왜 내가 이러고 있는지 이해가 안간다. ㅎ
'Data Science > Pandas' 카테고리의 다른 글
| [Pandas] 엑셀xlsx , csv파일로 내보내기 (0) | 2024.06.15 |
|---|---|
| [Pandas] query()로 불린 인덱싱 (2) | 2024.06.14 |
| [EDA] 데이터 합치기 .merge; inner join, left outer join, right outer join, full outer join (1) | 2024.06.09 |
| [EDA] 카테고리 분류, .groupby (0) | 2024.06.09 |
| [EDA] 카테고리 분류, .map() (3) | 2024.06.07 |