# 코드잇 데이터 사이언티스트 강의 듣는 중
<날짜와 시간 데이터 인덱싱하기>
- 불린 인덱싱을 하려면 datetime이 인덱스가 되어 있어야 함.
- .set_index()
#datetime으로 불러오기
order_df = pd.read_csv('data/order.csv', parse_dates =['order_time', 'shipping_time'])
#미리 불러왔으면, 데이터타입만 변경
delivery_df['order_time'] = pd.to_datetime(delivery_df['order_time']
#인덱스로 지정
order_df.set_index('order_time')
-->보면 시간이 순서대로 정렬되어 있지 않음.
- 정렬시켜줌
order_df = order_df.set_index('order_time').sort_index()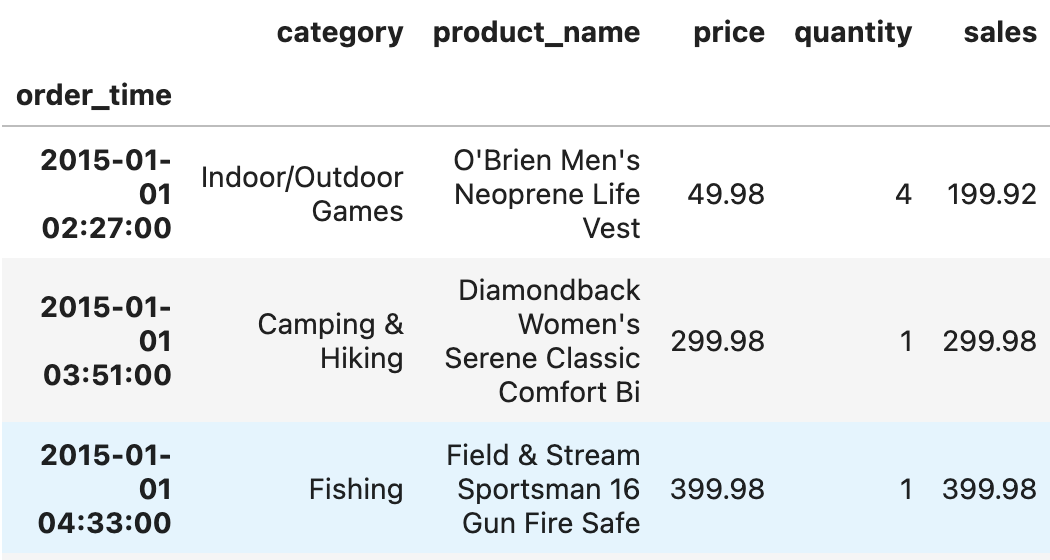
- datetime을 인덱스로 해 두면 값을 전부 넘겨줄 필요없이 일부만 넘겨도 됨.
- so, 공통된 값들을 불러오기가 더 수월함.
--> partial string indexing
order_df.loc['2015']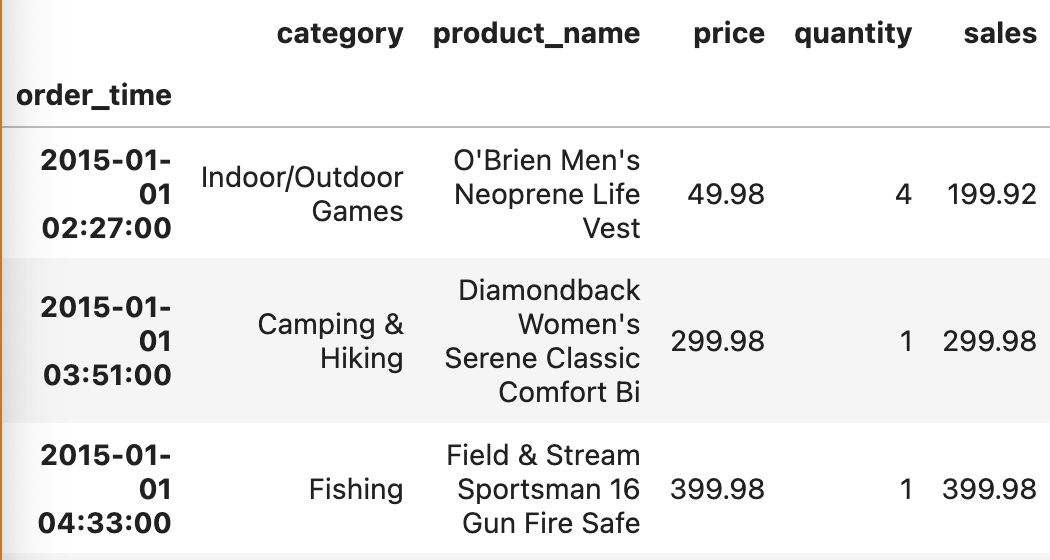
--> 인덱스 값을 전부 다 안 넣어줘도, '2015'가 포함된 값 전부를 불러옴.
- 임의로 조건을 더 추가할 수 있음.
#2015-06 만 가져오기
order_df.loc['2015-06']
# 해당 날짜만 가져오기
order_df.loc['2015-06-10']
#위랑 같은 값으로 10미만의 숫자는 0이 빠져도 됨
order_df.loc['2015-6-10']
- 슬라이싱도 가능
order_df.loc['2015':'2017']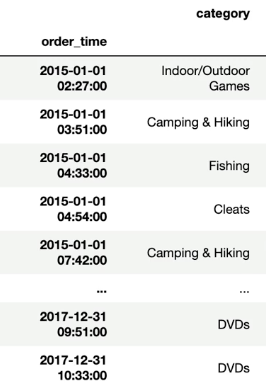
--> .loc는 '2017'(콜론 오른쪽 값)이 포함됨.
--> .iloc는 콜론 오른쪽 값이 포함 x
<날짜와 시간 데이터 더하기 빼기>
- datetime 데이터끼리 연산이 가능.
- timedelta : 두 시점 사이의 시간 차이를 나타낼 때 사용
order_df['shipping_time'] - order_df.index
#값
order_time
2015-01-01 02:27:00 4 days 10:48:00
2015-01-01 03:51:00 3 days 16:15:00
2015-01-01 04:33:00 5 days 13:28:00
2015-01-01 04:54:00 6 days 14:13:00
2015-01-01 07:42:00 4 days 09:23:00
...
2018-01-31 16:59:00 6 days 03:33:00
2018-01-31 17:20:00 1 days 16:56:00
2018-01-31 18:44:00 6 days 00:09:00
2018-01-31 21:53:00 1 days 20:57:00
NaT NaT
Length: 18050, dtype: timedelta64[ns]
--> 주문 시간과 배송시간의 차이를 확인후 이 값을 실제 배송 시간으로 저장함.
order_df['days_for_shipping(actual)'] = order_df['shipping_time'] - order_df.index
order_df.dtypes
--> 계산 값은 timedelta로 타입이 변경됨.
- 실제 배송시간이 예상시간보다 오래 걸렸는지를 확인하고자 함.
order_df['days_for_shipping(expected)'] < order_df['days_for_shipping(actual)']
#에러
TypeError: Invalid comparison between dtype=timedelta64[ns] and ndarray--> 둘의 타입이 다르기 때문에 에러가 남.
- then, 그냥 .to_timedelta()로 바꿔주면 됨
pd.to_timedelta(order_df['days_for_shipping(expected)'])
#값
order_time
2015-01-01 02:27:00 0 days 00:00:00.000000006
2015-01-01 03:51:00 0 days 00:00:00.000000006
2015-01-01 04:33:00 0 days 00:00:00.000000006
2015-01-01 04:54:00 0 days 00:00:00.000000006
2015-01-01 07:42:00 0 days 00:00:00.000000004
...
2018-01-31 16:59:00 0 days 00:00:00.000000006
2018-01-31 17:20:00 0 days 00:00:00.000000006
2018-01-31 18:44:00 0 days 00:00:00.000000006
2018-01-31 21:53:00 0 days 00:00:00.000000003
NaT 0 days 00:00:00.000000006
Name: days_for_shipping(expected), Length: 18050, dtype: timedelta64[ns]
--> 단위를 설정하지 않으면, 디폴트인 나노초 단위로 출력이 됨
- unit=''을 파라미터로 넣어서 단위를 설정해줌.
- D는 하루 단위, H는 시간 단위, T분 단위, S초단위
pd.to_timedelta(order_df['days_for_shipping(expected)'], unit='D')
#값
order_time
2015-01-01 02:27:00 6 days
2015-01-01 03:51:00 6 days
2015-01-01 04:33:00 6 days
2015-01-01 04:54:00 6 days
2015-01-01 07:42:00 4 days
...
2018-01-31 16:59:00 6 days
2018-01-31 17:20:00 6 days
2018-01-31 18:44:00 6 days
2018-01-31 21:53:00 3 days
NaT 6 days
Name: days_for_shipping(expected), Length: 18050, dtype: timedelta64[ns]
#저장
order_df['days_for_shipping(expected)'] = pd.to_timedelta(order_df['days_for_shipping(expected)'], unit='D')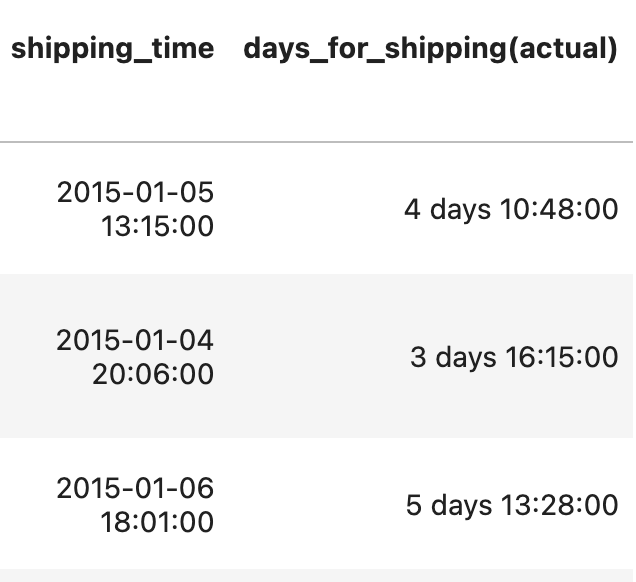
--> 값이 바뀜
- 이제는 불린 인덱싱이 가능함.
order_df['days_for_shipping(expected)'] < order_df['days_for_shipping(actual)']
#값
order_time
2015-01-01 02:27:00 False
2015-01-01 03:51:00 False
2015-01-01 04:33:00 False
2015-01-01 04:54:00 True
2015-01-01 07:42:00 True
...
2018-01-31 16:59:00 True
2018-01-31 17:20:00 False
2018-01-31 18:44:00 True
2018-01-31 21:53:00 False
NaT False
Length: 18050, dtype: bool
--> 새로운 벡터로 넣어줄 수 있음.
order_df['late_shipping'] = order_df['days_for_shipping(expected)'] < order_df['days_for_shipping(actual)']
order_df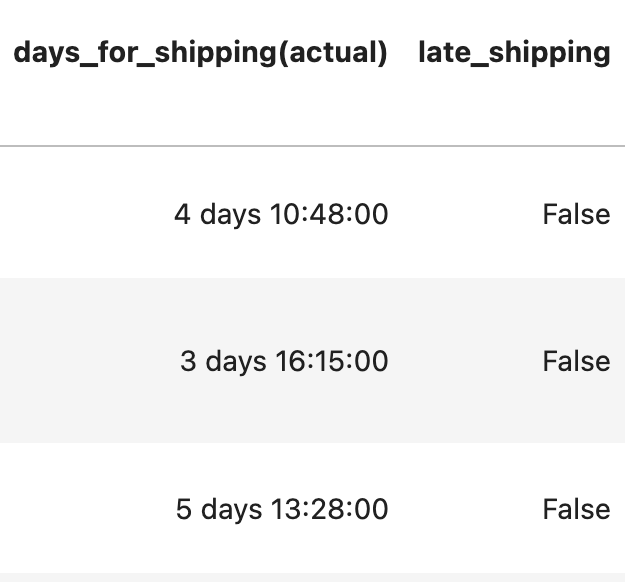
--> 개수가 궁금해지니깐. .value_counts()로 확인 가능.
order_df['late_shipping'].value_counts()
#값
late_shipping
False 14846
True 3204
Name: count, dtype: int64
order_df[order_df['late_shipping']]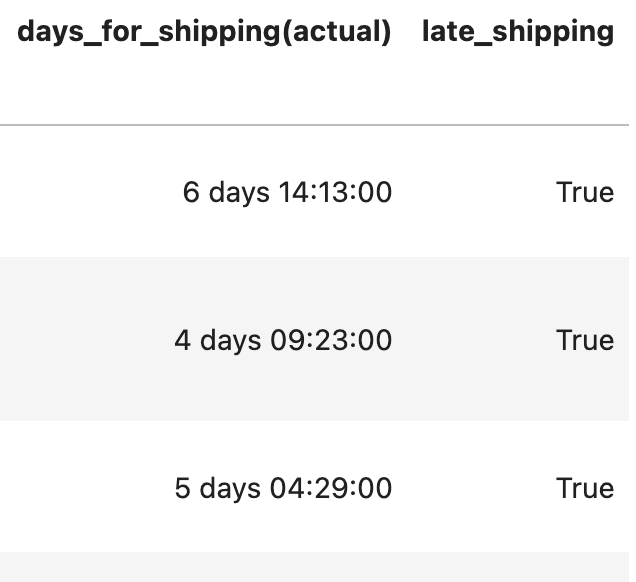
--> then, 늦게 배송된(True, 3204) 고객만 확인 가능합니다!
--> 이후에 서비스를 따로 보내던가 할 수 있음.
'Data Science > Pandas' 카테고리의 다른 글
| [데이터 전처리] 그룹 별로 분석하기 groupby(), category 타입, 멀티 인덱싱 (2) | 2024.06.26 |
|---|---|
| [데이터 전처리] 데이터 합치기) 같은 형식 concat() / 칼럼 기준 merge() / 인덱스 기준 join() (0) | 2024.06.25 |
| [데이터 전처리] 날짜와 시간 데이터 타입 설정하기, datetime (0) | 2024.06.24 |
| [데이터 전처리] 데이터 구간화 cut() or apply(), 람다함수와 apply() (0) | 2024.06.21 |
| [데이터 전처리] 새로운 값 계산하기, 정규화, 표준화, 과학적 표기법 (0) | 2024.06.20 |