# 코드잇 데이터 사이언티스트 강의 듣는 중
<결측값 missing value 찾기>
1) .info()
airbnb_df.info()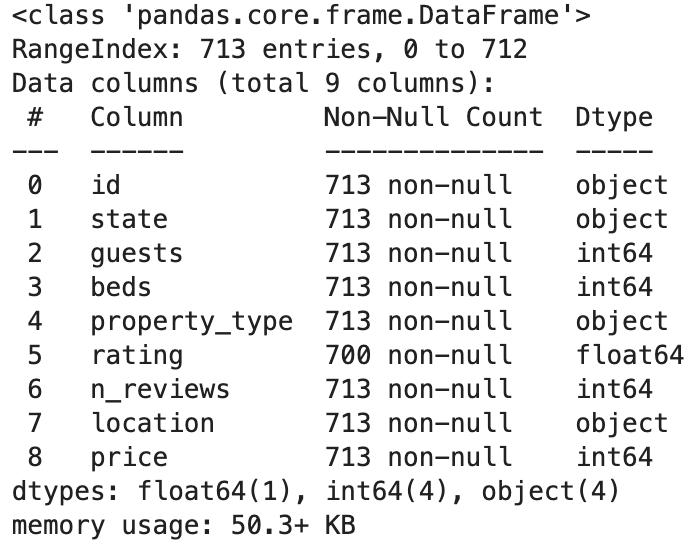
--> non-null count를 통해 다른 값들과 갯수가 다르면 null있다고 예측 가능.
2) .isna()
airbnb_df.isna() #결측값이 있으면 TRUE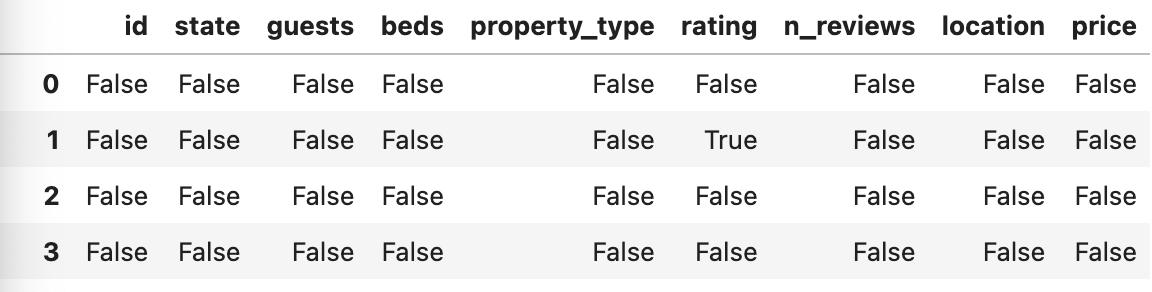
--> 결측 값 여부에 따라서 true or false
- 이거로는 총 개수 확인이 어렵기 때문에 .sum()을 해줌
airbnb_df.isna().sum()
--> 이러면 결측치 보기가 편함.
- 조건식으로 확인하려면, .any(axis=1)을 넣어줌.
airbnb_df.isna().any(axis=1) #any는 트루 값이 1개라도 있으면 트루 결측값 존재 확인.
--> 불리언 시리즈로 출력
--> 벡터 중 트루가 한 개라도 있으면 트루임.
- 불린 익덱싱을 해주면, 결측치만 불러올 수 있음.
airbnb_df[airbnb_df.isna().any(axis=1)]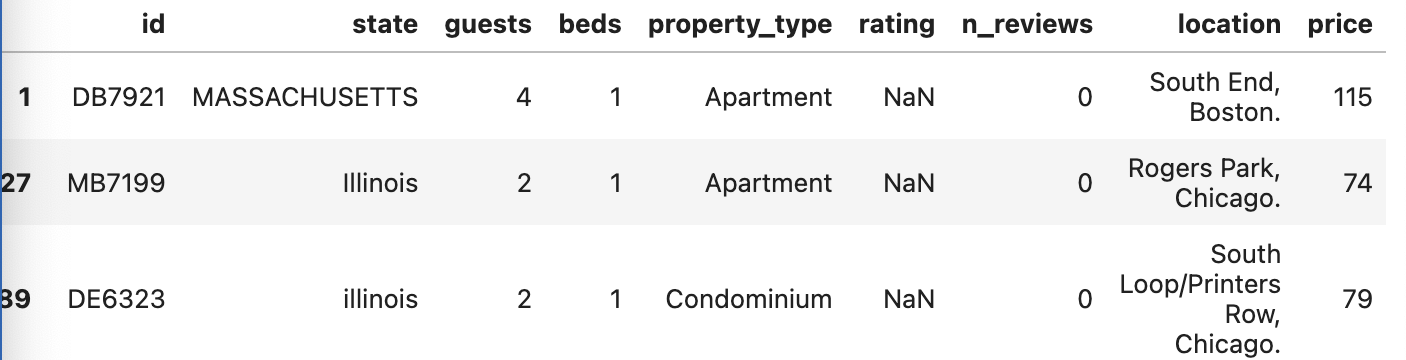
--> rating이 nan이기 때문에 결측치가 됨.
<결측값 처리하기>
1) 결측값 삭제하기
- 개수가 적어서 삭제해도 큰 영향 x or 컬럼이나 로우의 값이 거의 다 결측값일 때
- .dropna()
--> 간단하지만, 데이터 양이 줄어듬
airbnb_df.dropna()--> rows 수 확인해보면 줄어있음.
2) 결측값을 다른 값으로 채우기
- 연속형 데이터는 주로 평균 or 중간 값
- 범주형 데이터는 최빈값
- .fillna(평균)
--> 실제 값과 다를 수 있지만, 모든 데이터를 활용할 수 있음.
#평균
rating_mean = airbnb_df['rating'].mean()
#넣어주기
airbnb_df['rating'].fillna(rating_mean)
--> 값이 바뀌었음.
#확인
airbnb_df['rating'] = airbnb_df['rating'].fillna(rating_mean)
airbnb_df
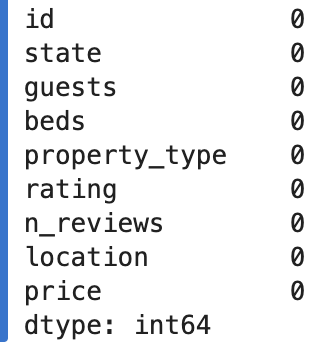
airbnb_df.isna().sum()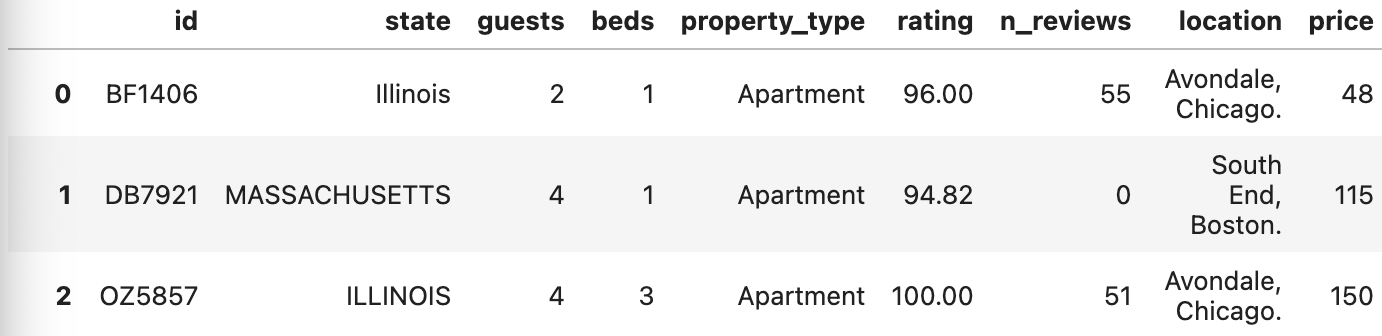
--> 2번 레이팅 채워짐.
<예시>
import pandas as pd
cellphone_df = pd.read_csv('data/cellphone.csv')
#결측치 확인
cellphone_df.isna().any(axis=1)
#처리한 후 인덱싱
cellphone_df['weight'] = cellphone_df['weight'].fillna(140)
cellphone_df[cellphone_df['year'] == 2021]
++ 난 업체에 데이터 수집을 맡겼기 때문에, 결측치가 있는 경우는 제외한 결과를 받았었다.
이상치를 제거했지..
- 아무리 생각해도 삭제를 하든 무슨 값을 넣든,, 무조건 편향이 생긴다.. 분포 상태에 따라서..
- 어떻게 보면 진짜.. 데분은 양심의 영역인듯.
'Data Science > Pandas' 카테고리의 다른 글
| [데이터 전처리] 이상치outlier 찾기, 처리하기 (0) | 2024.06.17 |
|---|---|
| [데이터 전처리] 중복값 duplicate value 찾기, 처리하기 (0) | 2024.06.17 |
| [Pandas] 엑셀xlsx , csv파일로 내보내기 (0) | 2024.06.15 |
| [Pandas] query()로 불린 인덱싱 (2) | 2024.06.14 |
| [Pandas] 엑셀xlsx 파일 불러오기 (0) | 2024.06.13 |