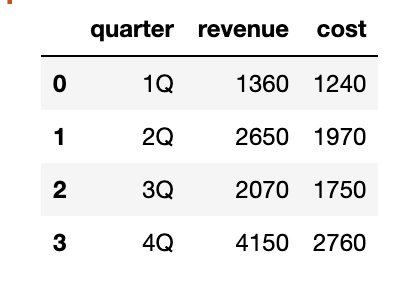
# 코드잇 데이터 사이언스 강의 듣는 중 - data에 따라서 대표치를 어떤 것으로 볼 지가 달라짐.- outlier가 크면, median은 mean보다 outlier의 영향을 덜 받기 때문에 사용- but, median은 전체 값의 분포가 달라져도 같을 수 있지만, mean은 값에 영향을 받기 때문에 median이 다 같으면 mean 더 좋은 대표치가 됨. --> numerical(수치형) data는 mean, median, mode를 구할 수 있음 - but categorical(범주형) data는 mean, median을 구할 수 없기에 mode가 대표치가 됨. + 수치형 데이터는 1) 이산형데이터 (값이 정확히 떨어짐; 오늘 마신 아메의 갯수) 와2) 연속형 데이터 (값이 정확하지 않음; 추정..