# 코드잇 데이터 사이언티스트 강의 듣는 중
<RFM 분석>
- RFM
- Recency: 고객이 얼마나 최근에 상품을 구매했는가? ; 기준 시점부터 가장 최근 구매일
- Frequency: 고객이 얼마나 자주 상품을 구매했는가? ; 기준 기간동안 상품을 구매한 횟수
- Monetary: 고객이 상품 구매에 얼마나 많은 돈을 썼는가? ; 기준 기간동안 구매한 상품의 총금액
--> RFM 분석은 위 세 항목을 토대로 고객의 가치를 판단해 고객을 분류하는 것을 의미함.
--> 더 최근에, 더 자주, 돈을 많이 쓸수록 가치가 큰 고객임.
- 아주 기본적이지만 효과적으로 고객을 분류하는 방범임.
--> 이렇게 분류된 고객 하나하나를 세그먼트 segment 라로 부름 --> 세그먼트에 따라서 고객 관리 적략을 수립하고 적용 가능.
- RFM 분석을 통해 고객 분류하기
- Recency,Frequency, Monetary관련 데이터가 있어야 함.

- Recency,Frequency, Monetary에 각각 등급을 매겨야 하는데,
- 각 등급마다 고객 수를 비슷하게 하거나, 구간의 길이를 똑같이 나누거나, 임의로 구간을 설정하기도.
- 강의에서 예시 등급과 그 기준으로 나눈 등급.

- 등급의 조합으로 세그먼트 나누기
- 각 항목당 3개의 등급이었기 때문에 3x3x3 =27 개의 세그먼트임.
- 각 세그먼트 별로 다른 전략을 세워서 고객 관리가 가능함.
- 모든 등급이 높으면 --> 지속적 쿠폰 발급, 이벤트
- 다 낮으면 --> 딱히 이탈에 관심 없음.
- monetary만 높으면 --> 더 자주 구매하도록 특별 쿠폰 등으로 유도
- recency, frequency는 높은데 monetary만 낮으면 충성도가 검증되었으니 상품을 맞춤 추천해서 추가 구매를 유도함.
--> 등급의 조합으로 세그먼트를 나누면 이론적으로 등급 개수의 3제곱임
--> so, 5개만 되도,, 125개가 나오기 때문에 너무 많아지면 맞춤형 전략을 짜는 게 너무 복잡해짐. 너무 작은 단위는 의미가 없을 수도 있고.
- 가중합으로 고객 지표를 구해 세그먼트 나누기

- 가중치의 총합은 1이어야 함.
- 가중치는 각 항목의 중요도에 따라서 설정 가능.
- 예, 배달앱은 monetary보다는 recency나 frequency가 더 중요할 수 있음. 반면 가전제품은 당연히 monetary가 제일 중요함.
- 이런 식으로 구간을 나눠서 최종 RFM 등급을 구할 수 있고, 나눠진 것이 곧 고객 세그먼트가 됨.
- 여러 등급이라고 해서 그게 꼭 != 세그먼트
--> 0-5점 지표여도 세그먼트를 4개로 나눠서 4점이상을 vip로 묶을 수도 있음. then, 복잡성이 줄어들고 맞춤형 전략을 수립하기도 더 쉬워짐.
- 만약에 3개의 가중치가 똑같다고 가정한 예시
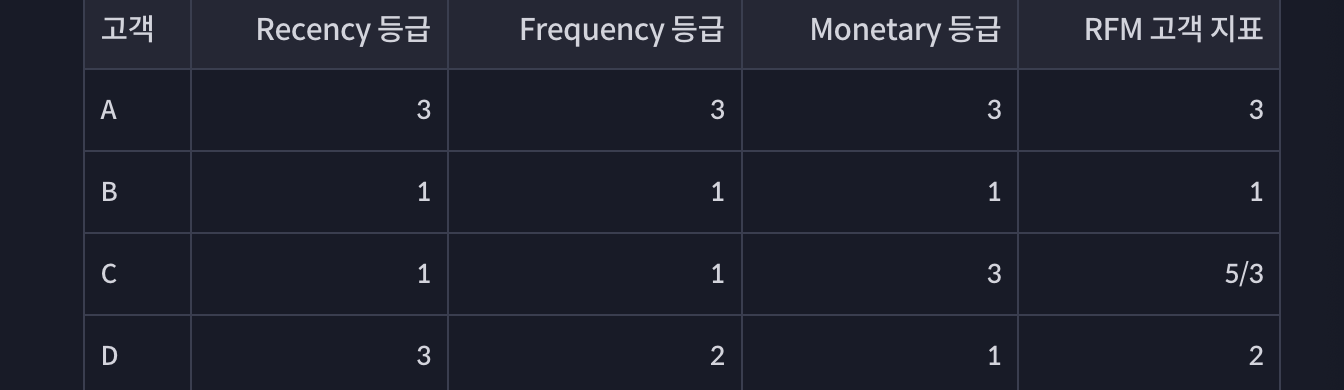
- FRM 등급을 3개로 하고, 고객 지표가 1이상 2미만이면 1등급, 2이상 3미만 2등급, 3이면 3등급으로 하면,
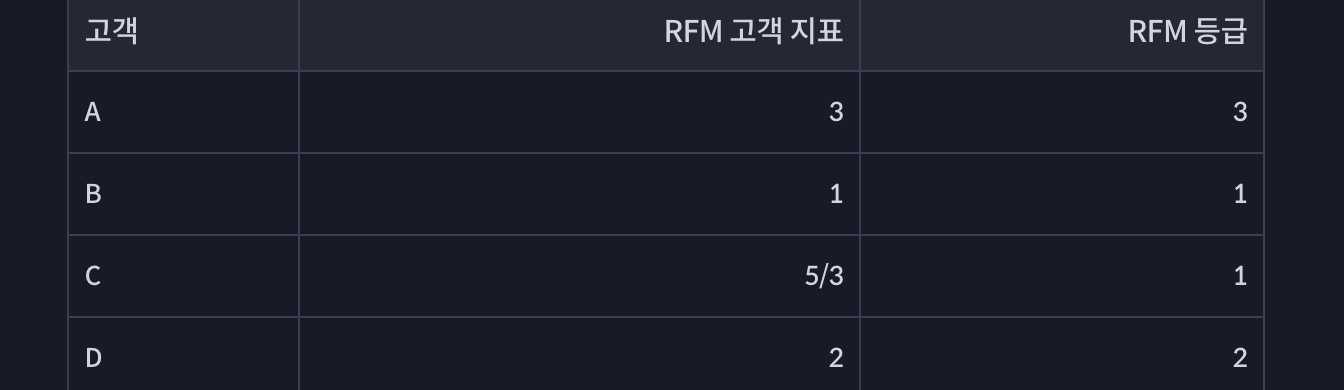
--> 간단히 3등급으로 구분 가능
- 매출 기여도를 고려한 가중치 조정
- 가중치를 적용해도 고객 세그먼트가 뚜렷하게 분류되지 않는다면 이를 조정하고 세그먼트를 재구성하는 것이 더 나음.
- 매출 기여도가 주로 뚜렷함의 기준이 됨.
- 한 세그먼트의 매출 기여도는 전체 매출 대비 해당 세그먼트 고객의 매출 비율로 구함.
--> 즉, 세그먼트 별로 뽑아보고 뚜렷하게 차이가 나는지, 모든 세그먼트가 비슷한지 확인하면 됨. 비슷하면 세그먼트가 제대로 분류가 안 된 것임. 즉, 가중치에서 문제가 있을 확률이 있으니 확인해야 함.
- 예, 가중치를 다 같게 두면
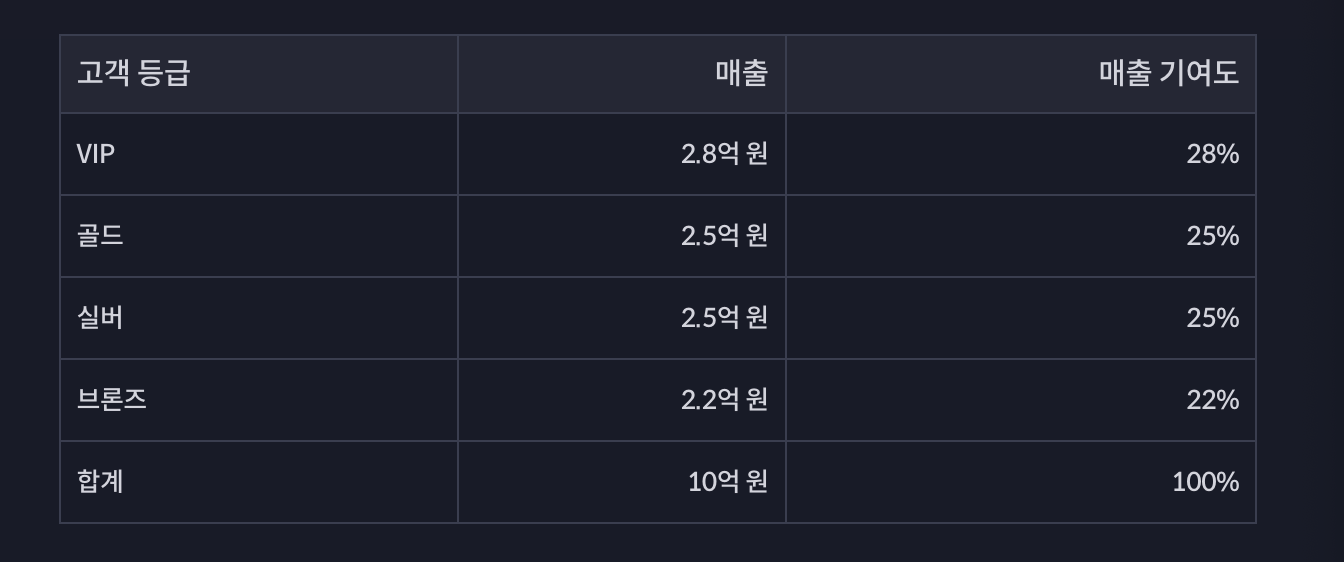
--> 세그먼트당 기여도 차이가 크지 않음
- monetary의 가중치를 0.6으로 높이면,
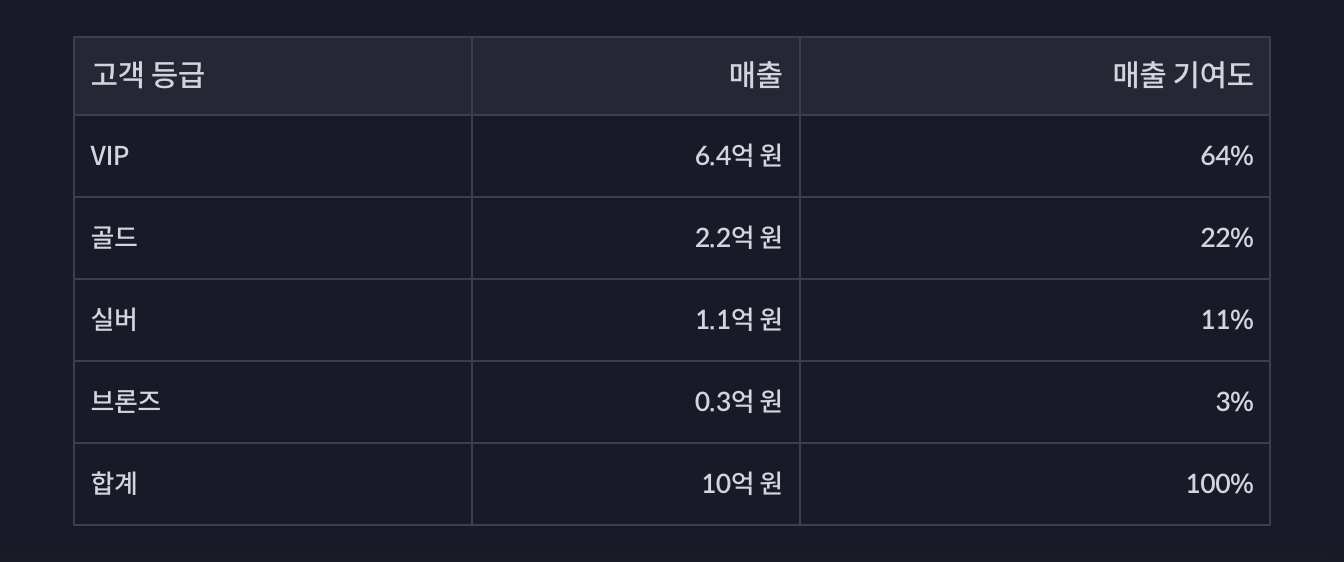
--> vip의 기여도가 명백히 높아졌고, 핵심 고객임이 확인됨.
'Data Science > Pandas' 카테고리의 다른 글
| [elice pandas] ',' , '-' replace 간단하게 하기, 형변환 (0) | 2025.05.12 |
|---|---|
| [elice 머신러닝] dataframe 문제.. (0) | 2025.05.06 |
| [pandas] 데이터 전처리 및 분석 연습2 (0) | 2024.07.08 |
| [pandas] 데이터 전처리 및 분석 연습1 (0) | 2024.07.04 |
| [데이터 전처리] 원하는 시간 간격으로 묶기 .resample() (0) | 2024.06.26 |