# 코드잇 데이터 사이언티스트 강의 듣는 중
... 에휴 안그래도 하면서 자동화를 더 하고 싶다고 생각했는데,
이번 채점 노트에서는 파이썬으로 자동화를 굉장히 많이했음..
........파이썬 강의를 더 들어야 할 듯..
아 머리아픔.
중간에 막혔던 부분들이 있어서 돌려가면서 할 것 같음.
<제주도 관광관련 데이터로 이것저것 확인해보기>
[코드잇 강의 가이드라인]
1. 데이터 불러오기
data 폴더 안에 있는 csv 파일을 DataFrame으로 불러옵시다.
- 읍면동별, 상세 업종별 카드 이용 데이터(2017년): jeju_card_region_2017.csv
- 읍면동별, 상세 업종별 카드 이용 데이터(2018년): jeju_card_region_2018.csv
- 읍면동 단위 내국인 유동인구 데이터: jeju_population.csv
2. 데이터 탐색 및 전처리
데이터를 간단히 탐색하고 전처리해 봅시다.
- 데이터 개수, 컬럼별 데이터 타입, 통계 정보, 결측값 존재 여부 등을 확인해 보세요.
- 각 컬럼이 어떤 값들로 이루어져 있는지 확인해 보세요.
- 2017년과 2018년 카드 데이터를 하나로 합쳐 주세요.
3. 데이터 분석
이용금액과 이용자수가 많은 업종과 지역 Top 10을 각각 뽑아 보세요.
- 인당 이용금액이 많은 지역 Top 10도 뽑아 봅시다.각 지역에서 어떤 업종들이 활성화되어 있는지도 함께 확인해 보세요.
- 데이터를 기반으로 카페 이용자수와 유동인구의 관계에 대해 살펴보세요.
- 카드 매출액 데이터와 유동인구 데이터를 하나로 합쳐서 보면 되겠죠? 어떻게 데이터를 합치는 게 좋을지 한번 고민해 보세요!
- 더 알아보고 싶은 게 있다면 원하는 대로 자유롭게 데이터를 탐색해 보세요!
- 내가 해봤을 막힌 문제들
- 사실 이번에는 이전연습 정리 보면서 수월하게 했다고 생각했는데, 중간에 막혀서.. 결국 해설로 넘어왔음.
1. 결측치 처리 문제; 일단.. 데이터를 보면서 업종 중에 데이터는 있으나 실질적 이용자수가 없던 업종들이 보였는데 지우는 게 맞는 지 확신을 못했음.
2. 파이썬 자동화 문제; 각 지역에서 어떤 업종들이 활성화되었는지를 확인하려고 했고 실제로 확인도 했으나, 각각의 코드를 치면서 python 반복문으로 하고 싶었는데, 값으로 하는 게 아니라 벡터가 바뀌어야 하는 것이라서, 리스트로 해야 하는 건지 생각만 해보고 결국 노가다로 했음.
3. 불린 인덱싱 문제; 유동인구 데이터와 기존 데이터를 합치기 전에 전처리를 할 때 불린 인덱싱에서 자꾸 에러가 났고, 데이터를 합치지 못했음.
4. 데이터 파악 문제; 카페...이용자수가 뭘 말하는 것인지 모르겠음. 내가 본 업종에서는 카페..? 는 없었는데
<데이터 탐색 및 전처리 >
- 정보 확인
- 정보 확인부분은 수월하게 넘겼음.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
jeju_reg_17_df = pd.read_csv('data/jeju_card_region_2017.csv')
jeju_reg_18_df = pd.read_csv('data/jeju_card_region_2018.csv')
jeju_pop_df = pd.read_csv('data/jeju_population.csv')
#데이터 탐색
print(jeju_reg_17_df.shape)
print(jeju_reg_18_df.shape)
print(jeju_pop_df.shape)
#head()
jeju_reg_17_df.head()
jeju_reg_18_df.head()
jeju_pop_df.head()
#info()
jeju_reg_17_df.info()
jeju_reg_18_df.info()
jeju_pop_df.info()
#describe(), 고정 소수점 표기법으로 맞춰줌
pd.options.display.float_format = '{:.3f}'.format
jeju_reg_17_df.describe(include='all')
jeju_reg_18_df.describe(include='all')
jeju_pop_df.describe(include='all')
- 2017, 18년 데이터 비교 및 전처리
- 여기서 내가 문제시 했던 파이썬을 활용해서 자동화를 하심. ... 진짜 아직 멀었다..
- 에후.. 하다보면 익숙해지겠지..
- nuique()
- 이건 새로 본 것 같은데, 이전에 배웠는데 기억을 못하는 것일 수도 있음.
- 어쨌든 unique한 값의 개수를 세주니깐 아주 편함.
- 지난번에 칼럼에 있는 내용만 확인하는 코드가 아니라 아예 함수화 해서 (이걸....생각했으면, 벡터별이라고 문제시 안했을 건데..ㅎㅎ) 코드를 만들어줌.
def print_unique_values(df):
object_columns = df.columns[df.dtypes == 'object']
for col in object_columns:
print(f'{col} 컬럼의 unique 값 개수: {df[col].nunique()}')
print(sorted(df[col].unique()), '\n')
print_unique_values(jeju_reg_17_df)
#값
연월 컬럼의 unique 값 개수: 12
['2017-01-01', '2017-02-01', '2017-03-01', '2017-04-01', '2017-05-01', '2017-06-01', '2017-07-01', '2017-08-01', '2017-09-01', '2017-10-01', '2017-11-01', '2017-12-01']
시군구명 컬럼의 unique 값 개수: 2
['서귀포시', '제주시']
읍면동명 컬럼의 unique 값 개수: 43
['건입동', '구좌읍', '남원읍', '노형동', '대륜동', '대정읍', '대천동', '도두동', '동홍동', '봉개동', '삼도1동', '삼도2동', '삼양동', '서홍동', '성산읍', '송산동', '아라동', '안덕면', '애월읍', '연동', '영천동', '예래동', '오라동', '외도동', '용담1동', '용담2동', '우도면', '이도1동', '이도2동', '이호동', '일도1동', '일도2동', '정방동', '조천읍', '중문동', '중앙동', '천지동', '추자면', '표선면', '한경면', '한림읍', '화북동', '효돈동']
업종명 컬럼의 unique 값 개수: 41
['건강보조식품 소매업', '골프장 운영업', '과실 및 채소 소매업', '관광 민예품 및 선물용품 소매업', '그외 기타 분류안된 오락관련 서비스업', '그외 기타 스포츠시설 운영업', '그외 기타 종합 소매업', '기타 갬블링 및 베팅업', '기타 대형 종합 소매업', '기타 수상오락 서비스업', '기타 외국식 음식점업', '기타 주점업', '기타음식료품위주종합소매업', '내항 여객 운송업', '마사지업', '면세점', '버스 운송업', '비알콜 음료점업', '빵 및 과자류 소매업', '서양식 음식점업', '수산물 소매업', '슈퍼마켓', '스포츠 및 레크레이션 용품 임대업', '여관업', '여행사업', '욕탕업', '육류 소매업', '일반유흥 주점업', '일식 음식점업', '자동차 임대업', '전시 및 행사 대행업', '정기 항공 운송업', '중식 음식점업', '차량용 가스 충전업', '차량용 주유소 운영업', '체인화 편의점', '피자, 햄버거, 샌드위치 및 유사 음식점업', '한식 음식점업', '호텔업', '화장품 및 방향제 소매업', '휴양콘도 운영업']
성별 컬럼의 unique 값 개수: 2
['남성', '여성']
print_unique_values(jeju_reg_18_df)
#값
연월 컬럼의 unique 값 개수: 12
['2018-01-01', '2018-02-01', '2018-03-01', '2018-04-01', '2018-05-01', '2018-06-01', '2018-07-01', '2018-08-01', '2018-09-01', '2018-10-01', '2018-11-01', '2018-12-01']
시군구명 컬럼의 unique 값 개수: 2
['서귀포시', '제주시']
읍면동명 컬럼의 unique 값 개수: 43
['건입동', '구좌읍', '남원읍', '노형동', '대륜동', '대정읍', '대천동', '도두동', '동홍동', '봉개동', '삼도1동', '삼도2동', '삼양동', '서홍동', '성산읍', '송산동', '아라동', '안덕면', '애월읍', '연동', '영천동', '예래동', '오라동', '외도동', '용담1동', '용담2동', '우도면', '이도1동', '이도2동', '이호동', '일도1동', '일도2동', '정방동', '조천읍', '중문동', '중앙동', '천지동', '추자면', '표선면', '한경면', '한림읍', '화북동', '효돈동']
업종명 컬럼의 unique 값 개수: 41
['건강보조식품 소매업', '골프장 운영업', '과실 및 채소 소매업', '관광 민예품 및 선물용품 소매업', '그외 기타 분류안된 오락관련 서비스업', '그외 기타 스포츠시설 운영업', '그외 기타 종합 소매업', '기타 대형 종합 소매업', '기타 수상오락 서비스업', '기타 외국식 음식점업', '기타 주점업', '기타음식료품위주종합소매업', '내항 여객 운송업', '마사지업', '면세점', '버스 운송업', '비알콜 음료점업', '빵 및 과자류 소매업', '서양식 음식점업', '수산물 소매업', '슈퍼마켓', '스포츠 및 레크레이션 용품 임대업', '여관업', '여행사업', '욕탕업', '육류 소매업', '일반유흥 주점업', '일식 음식점업', '자동차 임대업', '전시 및 행사 대행업', '정기 항공 운송업', '중식 음식점업', '차량용 가스 충전업', '차량용 주유소 운영업', '체인화 편의점', '택시 운송업', '피자, 햄버거, 샌드위치 및 유사 음식점업', '한식 음식점업', '호텔업', '화장품 및 방향제 소매업', '휴양콘도 운영업']
성별 컬럼의 unique 값 개수: 2
['남성', '여성']
- 이렇게 하면,, 정말 너무 수월해지고, 업종이랑 읍면동 개수가 같을까 코드 더 짜봐야 하나 싶었는데, 확인이 바로 됨.
- 근데 둘이 같은 값으로 동일한 지를 확인해야 함.
- 이 부분은 생각도 못했었는데,, 확인을 해야 하니깐, 코드를 또 짜줌..
- 진짜 for 문 없었으면 어쨌을까... 그리고 not in 은 이번에 처음 봤음.
for item in jeju_reg_17_df['업종명'].unique():
if item not in jeju_reg_18_df['업종명'].unique():
print(f'2017년에만 있는 값: {item}')
for item in jeju_reg_18_df['업종명'].unique():
if item not in jeju_reg_17_df['업종명'].unique():
print(f'2018년에만 있는 값: {item}')
#결과
2017년에만 있는 값: 기타 갬블링 및 베팅업
2018년에만 있는 값: 택시 운송업
- 각각이 없으니깐, 실제로 데이터가 몇 개나 되는 지 확인이 필요함.
- 데이터가 각각 1, 4개로 별로 없으니까 지워도 됨. --> 이걸 확신하지 못했는데, 었쨌든 양측의 결측치니까
print(jeju_reg_17_df[jeju_reg_17_df['업종명'] == '기타 갬블링 및 베팅업'].shape) # (1, 7)
print(jeju_reg_18_df[jeju_reg_18_df['업종명'] == '택시 운송업'].shape) # (4, 7)
#지워주기
jeju_reg_17_df = jeju_reg_17_df[jeju_reg_17_df['업종명'] != '기타 갬블링 및 베팅업']
jeju_reg_18_df = jeju_reg_18_df[jeju_reg_18_df['업종명'] != '택시 운송업']
- 읍면동명도 많으니깐 확인이 필요함.
- 출력 값이 없어서 다른 것이 없으니 냅두면 됨.
for item in jeju_reg_17_df['읍면동명'].unique():
if item not in jeju_reg_18_df['읍면동명'].unique():
print(f'2017년에만 있는 값: {item}')
for item in jeju_reg_18_df['읍면동명'].unique():
if item not in jeju_reg_17_df['읍면동명'].unique():
print(f'2018년에만 있는 값: {item}')
- 데이터 합치기는 같은 벡터니깐 .concat()으로 하면 됨.
jeju_reg_df = pd.concat([jeju_reg_17_df, jeju_reg_18_df])
jeju_reg_df.shape
#값
(54146, 7)
- 연월 컬럼 전처리
- 이 부분도.. 생각도 못했는데, 데이터를 보면서 달마다 걍 1일만 들어있네 싶긴 했는데.. 내버려뒀는데, 해설에서는 그러면 필요없는 데이터라고 지워줌.
- 정확하겐 :7까지만 가지고 오게 슬라이싱을 해줌.
jeju_reg_df['연월'].unique()
#값
array(['2017-01-01', '2017-02-01', '2017-03-01', '2017-04-01',
'2017-05-01', '2017-06-01', '2017-07-01', '2017-08-01',
'2017-09-01', '2017-10-01', '2017-11-01', '2017-12-01',
'2018-01-01', '2018-02-01', '2018-03-01', '2018-04-01',
'2018-05-01', '2018-06-01', '2018-07-01', '2018-08-01',
'2018-09-01', '2018-10-01', '2018-11-01', '2018-12-01'],
dtype=object)
#연월만 가져오도록
jeju_reg_df['연월'] = jeju_reg_df['연월'].str[:7]
jeju_reg_df.head()
<카드 이용이 많은 지역과 업종 알아보기 >
- 업종별 카드 이용 및 이용자수 top 10
- 이 부분은 .head(10)이랑 sort_values()수월하게 넘겼음.
- 나름 바플랏도 그렸음.
groupby_sector = jeju_reg_df.groupby('업종명').sum(numeric_only=True)
#top 10
groupby_sector.sort_values(by='이용금액', ascending=False).head(10)
groupby_sector.sort_values(by='이용자수', ascending=False).head(10)
#인당 이용금액
groupby_sector['인당이용금액'] = groupby_sector['이용금액'] / groupby_sector['이용자수']
groupby_sector.sort_values(by='인당이용금액', ascending=False).head(10)
- 값을 보면서 버스 운송업이 5라 너무 작다고 생각은 했지만, 지우진 않았는데, 해설은 지우심
#버스 운송업이 너무 작음.
groupby_sector.sort_values(by='이용자수').head(10) #5
#버스 운송업 제외
jeju_reg_df = jeju_reg_df[jeju_reg_df['업종명'] != '버스 운송업']
- 다시 하면,
# 업종별 합계 및 인당 이용금액 계산
groupby_sector = jeju_reg_df.groupby('업종명').sum(numeric_only=True)
groupby_sector['인당이용금액'] = groupby_sector['이용금액'] / groupby_sector['이용자수']
# 인당 이용금액 상위 10개 업종
groupby_sector.sort_values(by='인당이용금액', ascending=False).head(10)
--> 지우는 것 빼고 똑같이 했음.
--> 근데.. 난 플랏 그렸는데.. 역시 안 그려도 되는 것이었음ㅎ
--> 그것 때문에 자동화 하고 싶었는데..ㅎ
- 읍면동별 카드 이용 및 이용자수 top 10
- 이 부분은 .head(10)이랑 sort_values()수월하게 넘겼음. 위랑 같음.
groupby_reg = jeju_reg_df.groupby('읍면동명').sum(numeric_only=True)
#top 10
groupby_reg.sort_values(by='이용금액', ascending=False).head(10)
groupby_reg.sort_values(by='이용자수', ascending=False).head(10)
- 인당 소비가 많은 지역에서 활성화된 업종
- 여기가.. 잘 안됐음.
- 해설은 5개만 뽑아서 변수로 담았음.
- 이때 head가 아니라 .iloc[:5]으로 해줬음... --> 인덱스로 못하나 했는데,, 그렇지.. 슬라이싱 하면 되자나..
#인당 소비
groupby_reg['인당이용금액'] = groupby_reg['이용금액'] / groupby_reg['이용자수']
groupby_reg.sort_values(by='인당이용금액', ascending=False).iloc[:5]
#변수에 담아줌.
top5_region = groupby_reg.sort_values(by='인당이용금액', ascending=False).iloc[:5].index
top5_region
#값
Index(['예래동', '영천동', '용담2동', '연동', '일도1동'], dtype='object', name='읍면동명')
......이게.. for문으로 활용해야 했네..
- 하.. 진짜 파이썬 강의를 들어야 할 듯.
- 읍면동과 업종을 groupby로 빼준 것은 했으나, 그 다음을 어떻게 해야 할지 몰랐는데,
- top5지역에 for문을 돌려서 이용금액이 많은 업종을 출력하게 함....
- .tolist()로 리스트로 만들어줌.
groupby_reg_sec = jeju_reg_df.groupby(['읍면동명', '업종명']).sum(numeric_only=True).reset_index()
for reg in top5_region:
reg_df = groupby_reg_sec[groupby_reg_sec['읍면동명'] == reg]
print(reg, reg_df.sort_values(by='이용금액', ascending=False).iloc[:5]['업종명'].tolist())
#값
예래동 ['호텔업', '한식 음식점업', '차량용 주유소 운영업', '골프장 운영업', '체인화 편의점']
영천동 ['차량용 주유소 운영업', '슈퍼마켓', '한식 음식점업', '골프장 운영업', '호텔업']
용담2동 ['면세점', '한식 음식점업', '자동차 임대업', '차량용 주유소 운영업', '관광 민예품 및 선물용품 소매업']
연동 ['정기 항공 운송업', '한식 음식점업', '일반유흥 주점업', '슈퍼마켓', '체인화 편의점']
일도1동 ['스포츠 및 레크레이션 용품 임대업', '수산물 소매업', '한식 음식점업', '과실 및 채소 소매업', '체인화 편의점']
<유동인구가 많은 지역>
- 카페 매장이 들어가면 좋을 곳
- ..... 아니 난....업종에 카페 매장이 있는 줄 알고 보다가.. 이게 뭔소리야 내가 뭘 놓친거야 하고 있었 잖아.......하..
- 그게 아니라 매장이 들어가도록 유동인구가 많은 지역을 찾는 거였음..
--> 내가 데이터를 잘못 파악한 게 아니었음..
jeju_pop_df.head()
print_unique_values(jeju_pop_df)
#값
시군구명 컬럼의 unique 값 개수: 2
['서귀포시', '제주시']
읍면동명 컬럼의 unique 값 개수: 43
['건입동', '구좌읍', '남원읍', '노형동', '대륜동', '대정읍', '대천동', '도두동', '동홍동', '봉개동', '삼도1동', '삼도2동', '삼양동', '서홍동', '성산읍', '송산동', '아라동', '안덕면', '애월읍', '연동', '영천동', '예래동', '오라동', '외도동', '용담1동', '용담2동', '우도면', '이도1동', '이도2동', '이호동', '일도1동', '일도2동', '정방동', '조천읍', '중문동', '중앙동', '천지동', '추자면', '표선면', '한경면', '한림읍', '화북동', '효돈동']
성별 컬럼의 unique 값 개수: 2
['남', '여']
연령대 컬럼의 unique 값 개수: 9
['10대', '10세미만', '20대', '30대', '40대', '50대', '60대', '70대', '80대이상']
- 읍면동명에 방문인구 확인
jeju_pop_df.groupby('읍면동명').sum(numeric_only=True).sort_values(by='방문인구', ascending=False).iloc[:10]
--> top10 확인...
- 데이터 합치기
- 일단 데이터를 살펴보면, 둘이 좀 다름. 이거 전처리 하다가.. 막혔음.
jeju_reg_df.head()
jeju_pop_df.head()
--> 연월일이..정수형임.
--> 이거 바꾸고 싶었는데..
- 연월일이 정수형 숫자 타입으로 값들이 길게 나옴
jeju_pop_df['연월일'].unique()
.....하 그러네 쪼개서 더해주면 되는데, 어떻게 중간에 '-'를 삽입할 지를 고민하고 있었음...
- 일단 문자열로 바꾸고, 연도와 월을 나누고 그 사이에 -를 넣으면 됨..
jeju_pop_df['연월일'] = jeju_pop_df['연월일'].astype('string')
jeju_pop_df['연월'] = jeju_pop_df['연월일'].str[:4] + '-' + jeju_pop_df['연월일'].str[4:6]
- .......... 성별도 불린 인덱싱이 왜 안되지? 왜 한 성으로 되는 거지.. 이러고 있었는데.. 바보임.. 그냥..
- 그냥. '성'을 추가하면 됨..하..
- 아직 멀었다 나는..
jeju_pop_df['성별'] = jeju_pop_df['성별'] + '성'
jeju_pop_df.head()
--> 그럼 같아짐....
- 이젠 groupby 해서 다 구하면 됨..
groupby_pop = jeju_pop_df.groupby(['연월', '시군구명', '읍면동명', '성별']).sum(numeric_only=True).reset_index()
groupby_pop.head()
--> 그룹바이를 한 값으로 합침..
--> 연령대, 연월일을 빼려고 그런 듯.
--> 즉, 제발... 없애는 게 아니라 제외하고 새로 만든다고 생각하자.
- 나는 다 합쳐야 한다고 생각했는데, 굳이 그럴 필요없이 적은 유동인구에 맞춰서 합침.
- 사실, 카페 위치 찾는 데에 다른 게 필요 없으니깐
- so, left outer join을 해줌. 공통이 되는 4개 컬럼이 기준이기 때문에 on 리스트에 넣어줌.
jeju_df = pd.merge(jeju_reg_df, groupby_pop, how='left', on=['연월', '시군구명', '읍면동명', '성별'])
jeju_df.head()
- 카페 소비가 활성화된 지역?
- 카페 업종.. ^^ 검색을 하는 것이구나.. .
- 그럼 나의 의문이 맞았군...생각보다 전부 다 알아서 해야 하는 것이었네..
jeju_df['업종명'].unique()
#값
array(['건강보조식품 소매업', '기타음식료품위주종합소매업', '기타 주점업', '기타 외국식 음식점업',
'그외 기타 종합 소매업', '그외 기타 분류안된 오락관련 서비스업', '일반유흥 주점업', '비알콜 음료점업',
'일식 음식점업', '중식 음식점업', '차량용 가스 충전업', '차량용 주유소 운영업',
'스포츠 및 레크레이션 용품 임대업', '체인화 편의점', '한식 음식점업', '전시 및 행사 대행업', '호텔업',
'빵 및 과자류 소매업', '수산물 소매업', '여행사업', '여관업', '화장품 및 방향제 소매업', '욕탕업',
'육류 소매업', '서양식 음식점업', '슈퍼마켓', '과실 및 채소 소매업', '골프장 운영업', '자동차 임대업',
'관광 민예품 및 선물용품 소매업', '피자, 햄버거, 샌드위치 및 유사 음식점업', '휴양콘도 운영업',
'그외 기타 스포츠시설 운영업', '기타 대형 종합 소매업', '내항 여객 운송업', '마사지업',
'기타 수상오락 서비스업', '면세점', '정기 항공 운송업'], dtype=object)
- 기타음식료품위주종합소매업, 비알콜 음료점업 --> 둘 중에 검색시 비알콜 음료점업에 속함.
- 생각보다 능동적인 과제 였음..ㅎ
cafe_df = jeju_df[jeju_df['업종명'] == '비알콜 음료점업']
cafe_df.groupby('읍면동명').sum(numeric_only=True).sort_values(by='이용금액', ascending=False).iloc[:10]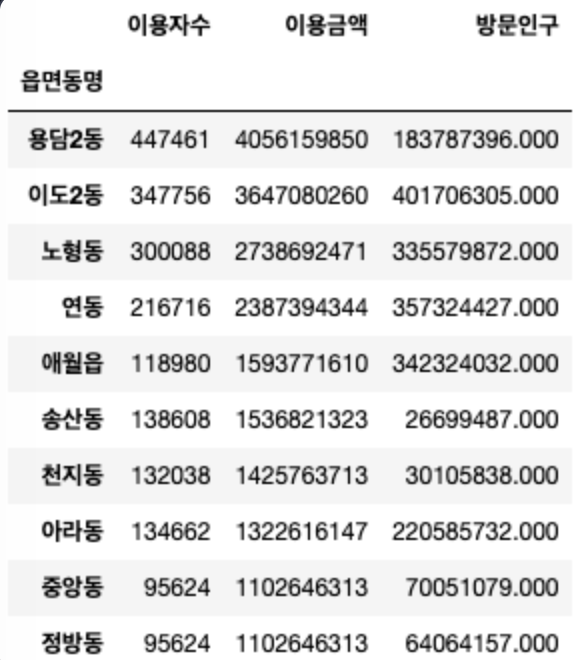
--> 데이터 프레임의 카페 이용 금액 상위 10개와 겹치는 곳이 6개라서, 카페 이용금액과 유동인구가 관련됨.
- 카페와 유동인구 관계 시각화
- 스캐터로 살펴봄.
- 여기까지.. 왔으면 좋았을 텐데 아쉬움.
# Windows
plt.rc('font', family='Malgun Gothic')
# macOS
plt.rc('font', family='AppleGothic')
sns.scatterplot(cafe_df, x='방문인구', y='이용금액')
plt.title('비알코올 음료점업의 방문 인구와 카드 이용 금액')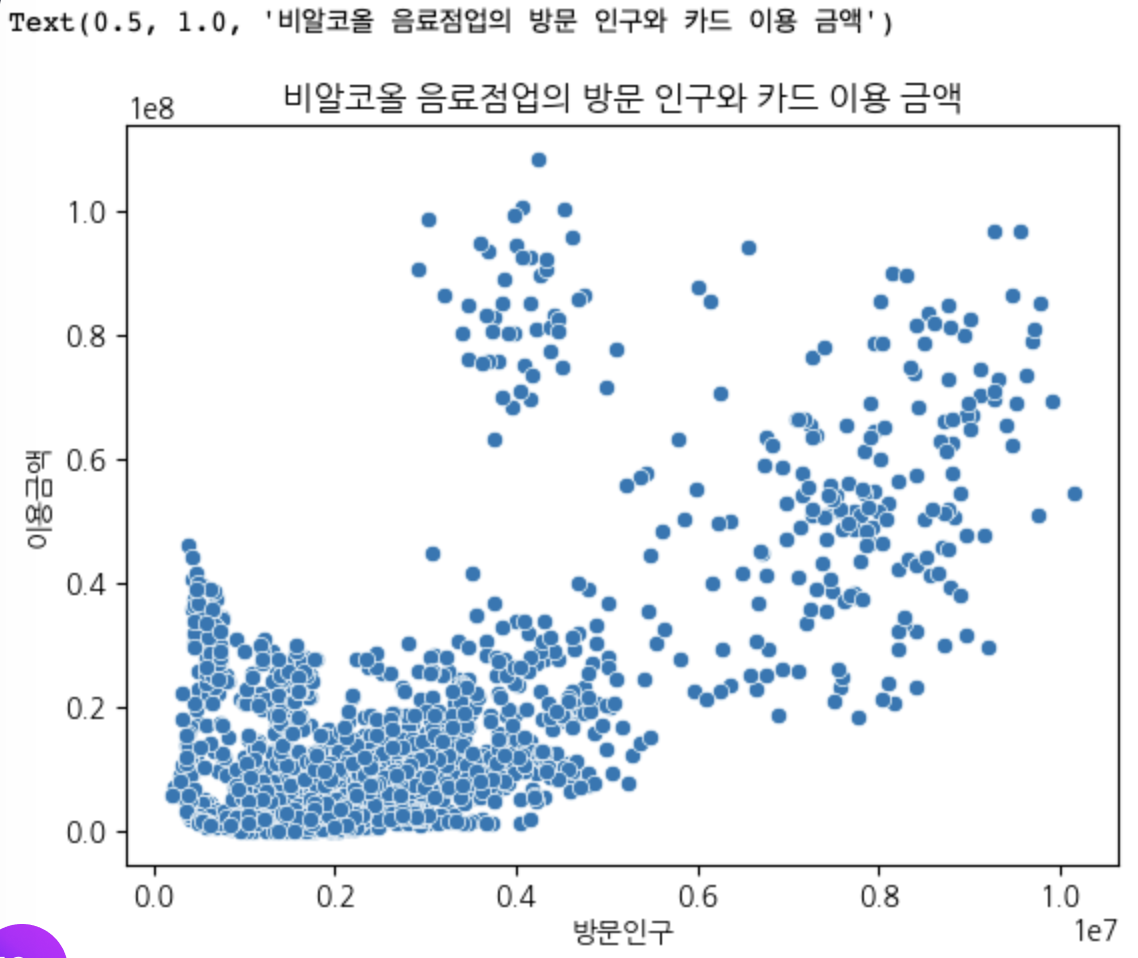
--> 이정도면 상관이 있음.
--> 상관계수 확인해야 함.
cafe_df.corr(numeric_only=True)
--> .63은 양의 상관이자 중간정도 상관이지만 었쨌든 분명한 관계가 있음.
- 혹시나 카페가 아닌 모든 데이터를 돌리면,
sns.scatterplot(jeju_df, x='방문인구', y='이용금액')
plt.title('전체 업종의 방문 인구와 카드 이용 금액')
--> 상관 없다고 봐야함
--> 값도 0.16으로 매우 낮은 상관.. 사실상 없음.
+++ 이렇게만 데이터 전처리를 할 수 있으면 참 좋을 텐데
아직까지 정돈된 데이터를 통계만 돌리는 이론적인 것에 너무 익숙해져 있는 듯하다..
++ 커머셜에 가까워서.. 씁.. 하여간 계속 해보쟈
'Data Science > Pandas' 카테고리의 다른 글
| [elice 머신러닝] dataframe 문제.. (0) | 2025.05.06 |
|---|---|
| [pandas] RFM분석 (2) | 2024.07.14 |
| [pandas] 데이터 전처리 및 분석 연습1 (0) | 2024.07.04 |
| [데이터 전처리] 원하는 시간 간격으로 묶기 .resample() (0) | 2024.06.26 |
| [데이터 전처리] 피벗 테이블 .pivot_table() (2) | 2024.06.26 |